
 NYP-AI
NYP-AINYP AI hosted its first-ever Unsupervised Learning event on 8th May 2021. Armed with detailed slides and concise code, we were ready to introduce a new Machine Learning paradigm to our members, through two of its more popular applications: Clustering and Dimensionality Reduction
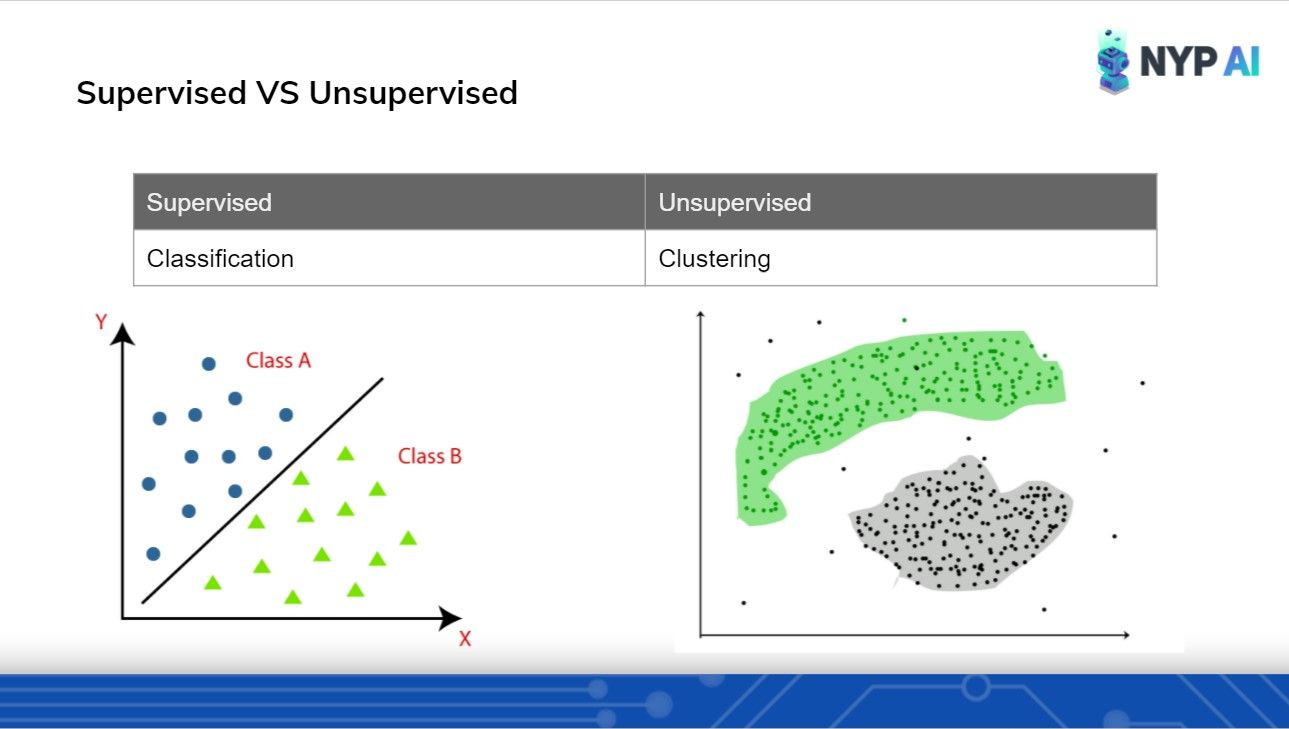
To start off, we cleared all misconceptions regarding Supervised vs Unsupervised learning. This involved providing side-by-side comparisons of their definitions, algorithms and applications.
Clustering: K-Means
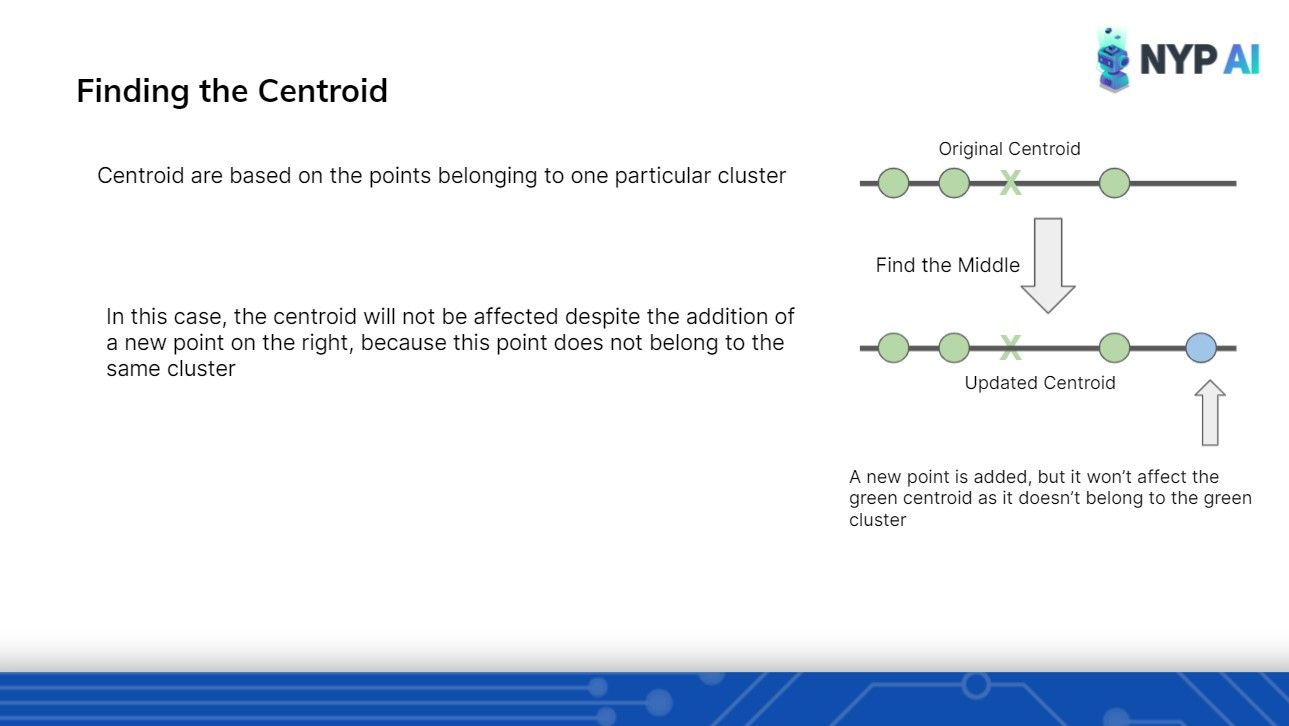
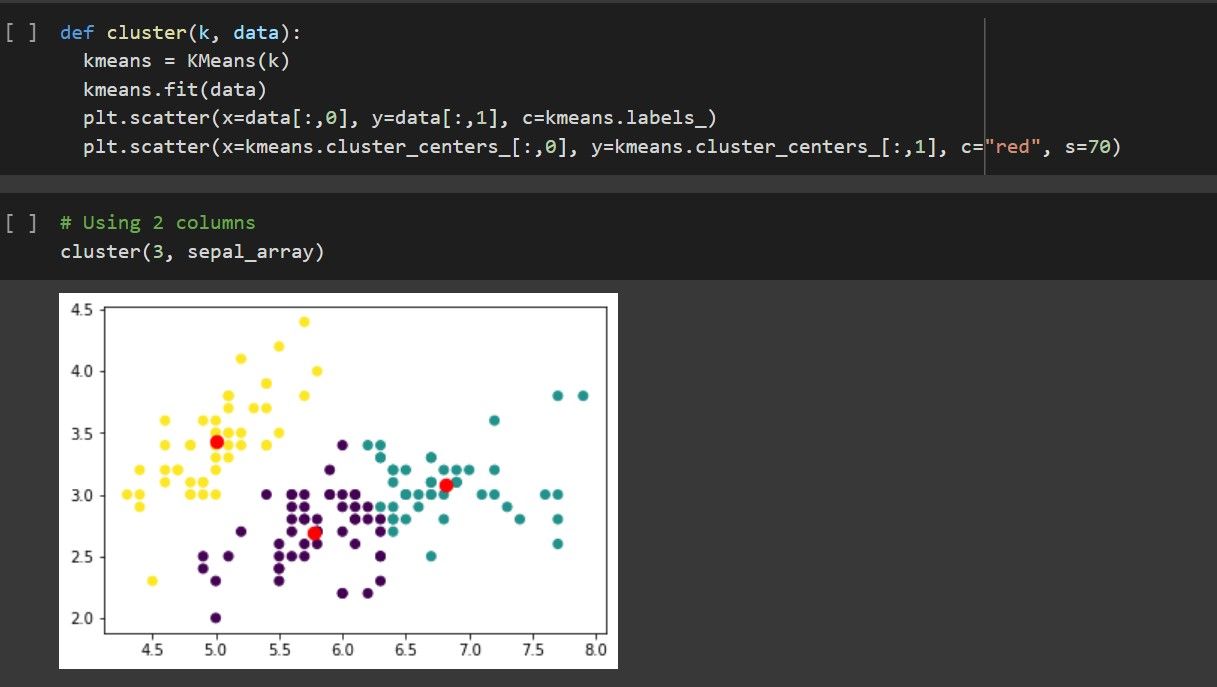
Moving on to our first Algorithm of the day: Clustering with K-Means. With clear diagrams to aid our members' understanding, we were able to get the point across quickly.

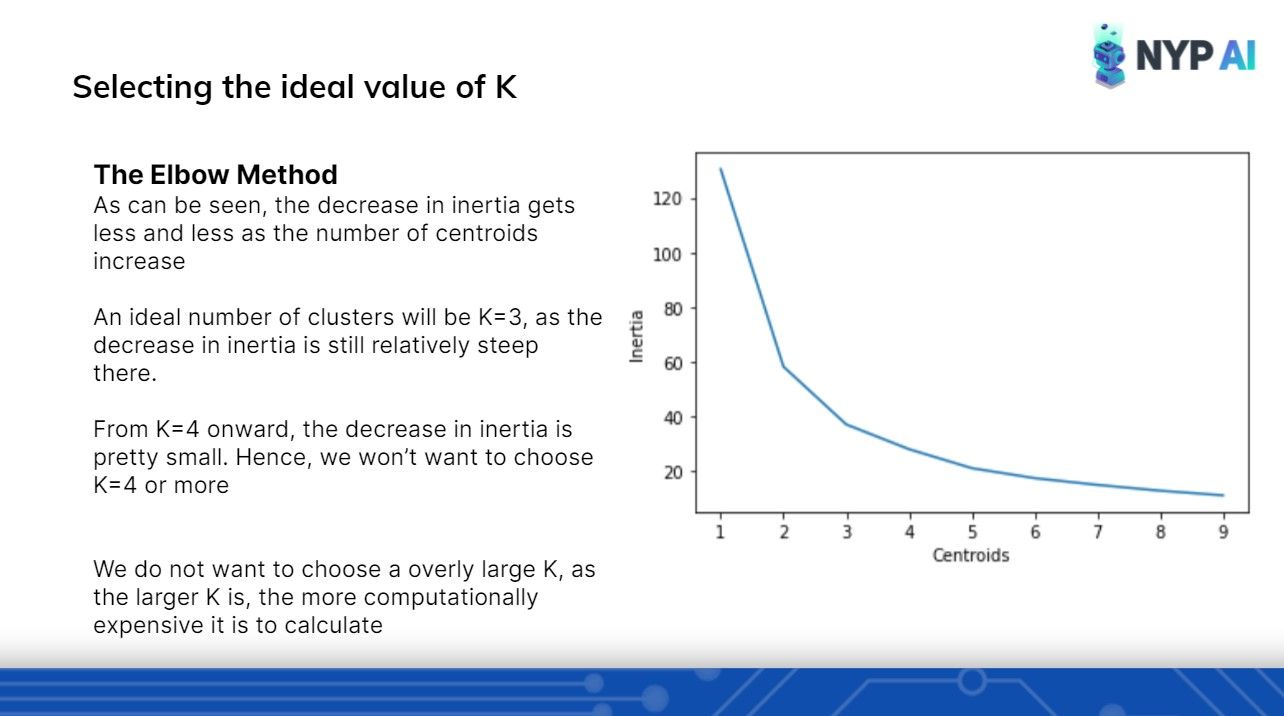
Unsure of how many clusters to initialize? We got that covered too :)
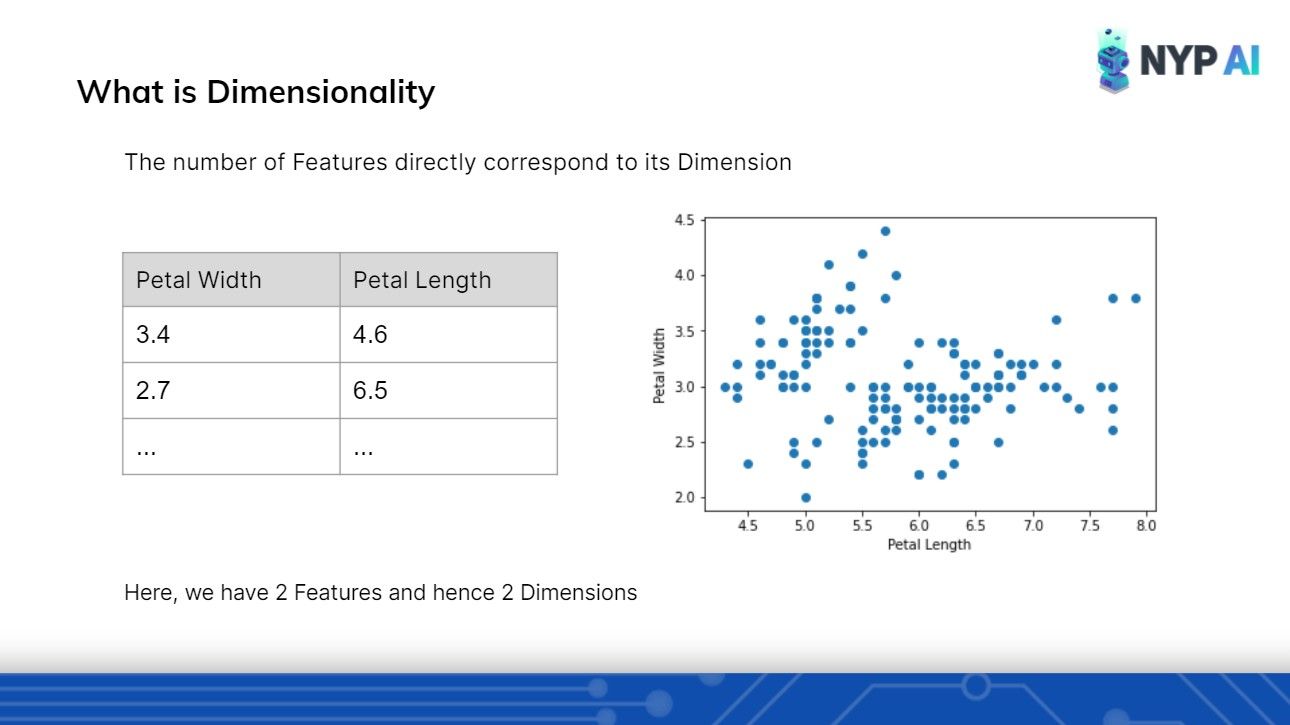
Dimensionality Reduction: PCA
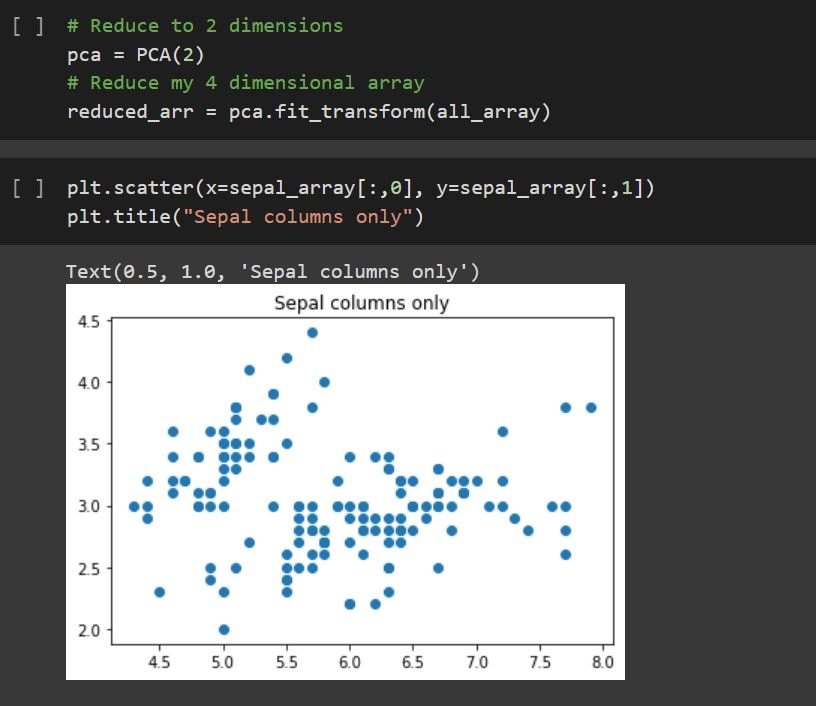
Moving on to a slightly more difficult concept - Dimensionality Reduction with PCA. Notwithstanding the tough visualizations required to understand, we were able to paint a clear picture using simple diagrams.

What better way to understand something than to apply it 🤷.... To end off our theory sessions, we implemented these exact algorithms in code. Having physically implemented these algorithms, our participants were now confident in using them for their own datasets.
Till then ~
Not as hard as it seemed, eh? Hoped everyone managed to learn something from today's session. Until then ~ 😊
