NYP AI Summer Camp 2021 is the second AI Summer Camp hosted by NYP AI, held from 20th September - 24th September, 2pm - 4:30pm daily. This time, we dabbled into applicable and interesting AI, including AI Stock Prediction, Face Detection & Tweets impersonation...
 NYP-AI
NYP-AIDay 1: Computer Vision
Diving into Day 1, we covered the Open-CV library, including how to read images and capture live frames from our computer's camera...

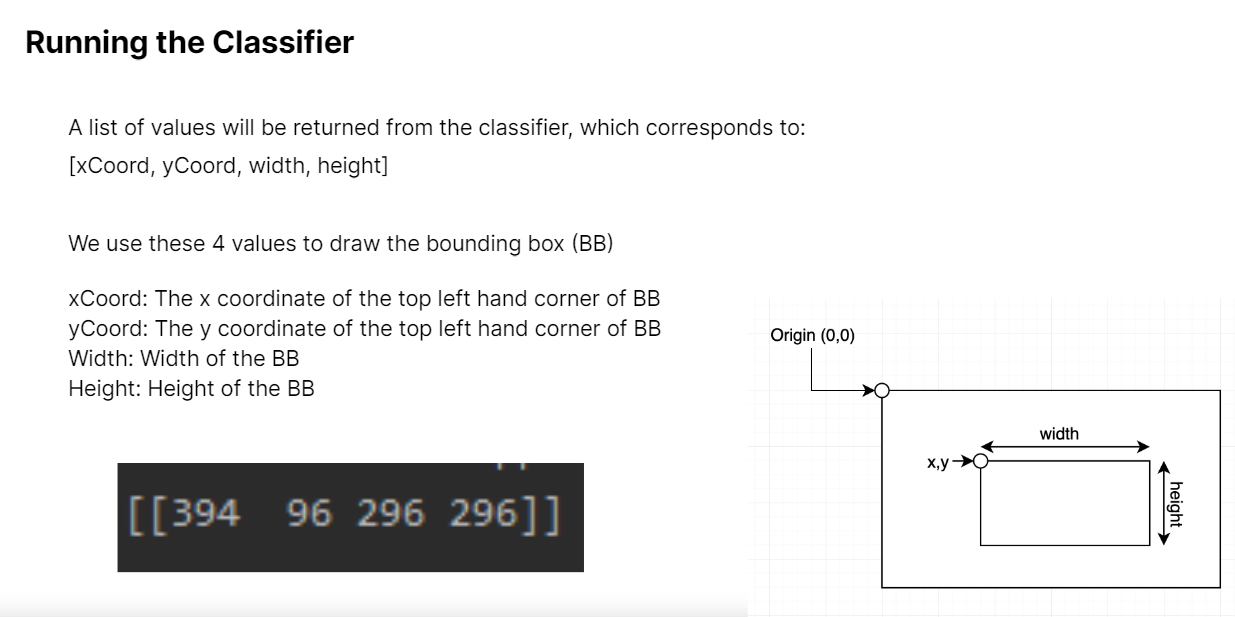
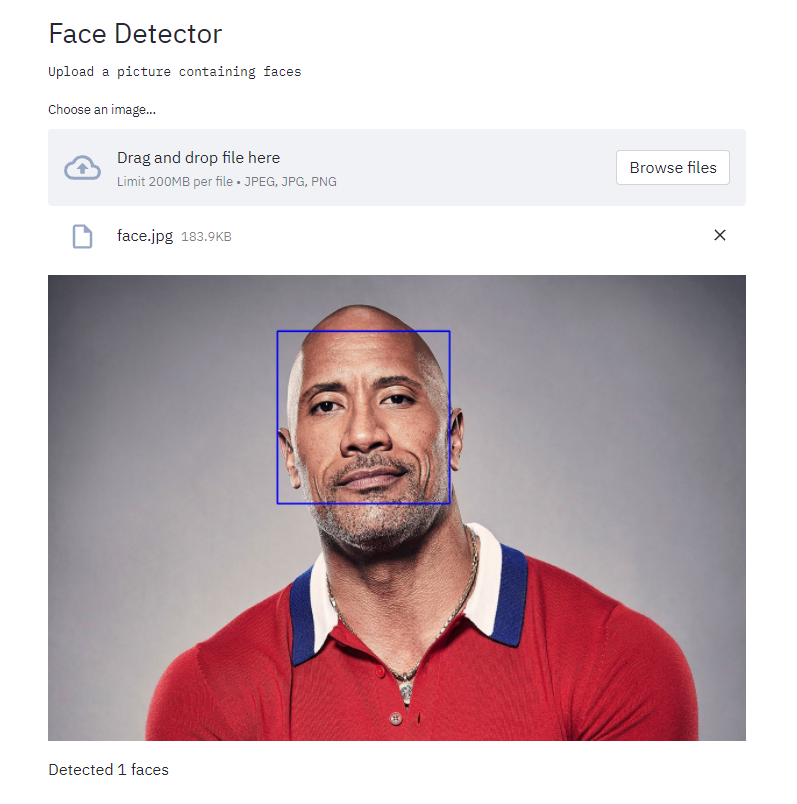
We went on to Object Detection, utilizing CV2's inbuilt CascadeClassifier. From converting images to grayscale, to outputting the bounding boxes, the entire pipeline was coded out.
Finally, we utilized Streamlit to host our model online. Using Github to store our code, and the Streamlit Sharing app, we were able to place our website on the World Wide Web...
Day 2: Natural Language Processing
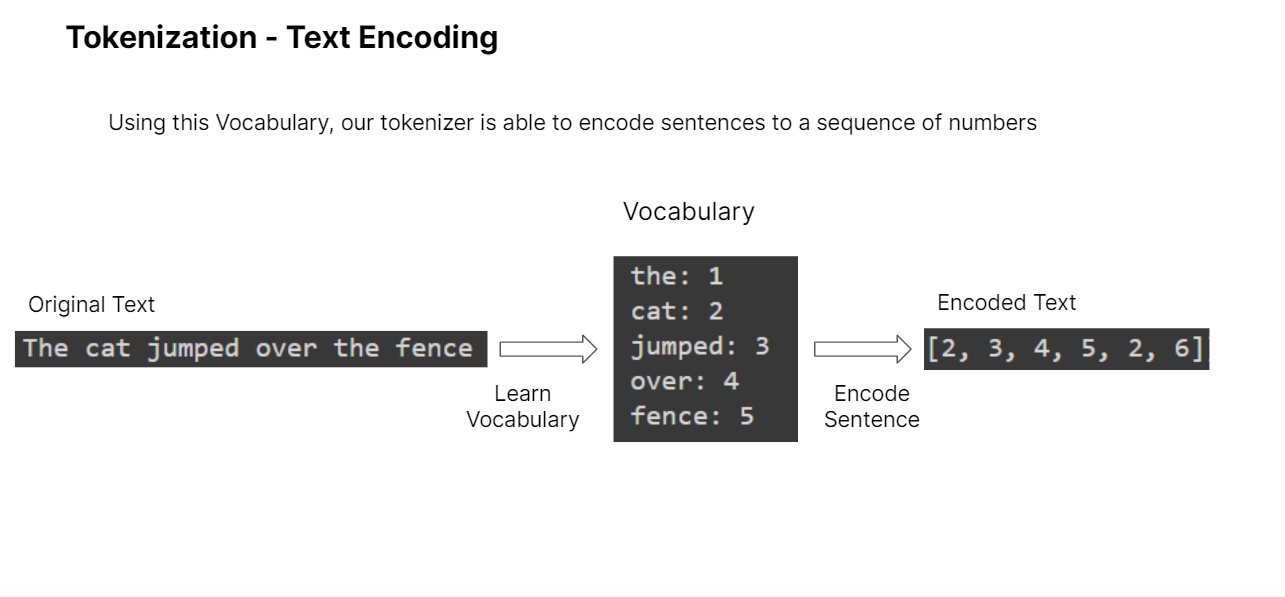
Starting off Day 2, two preprocessing techniques for text was covered: Tokenization & Word Stemming
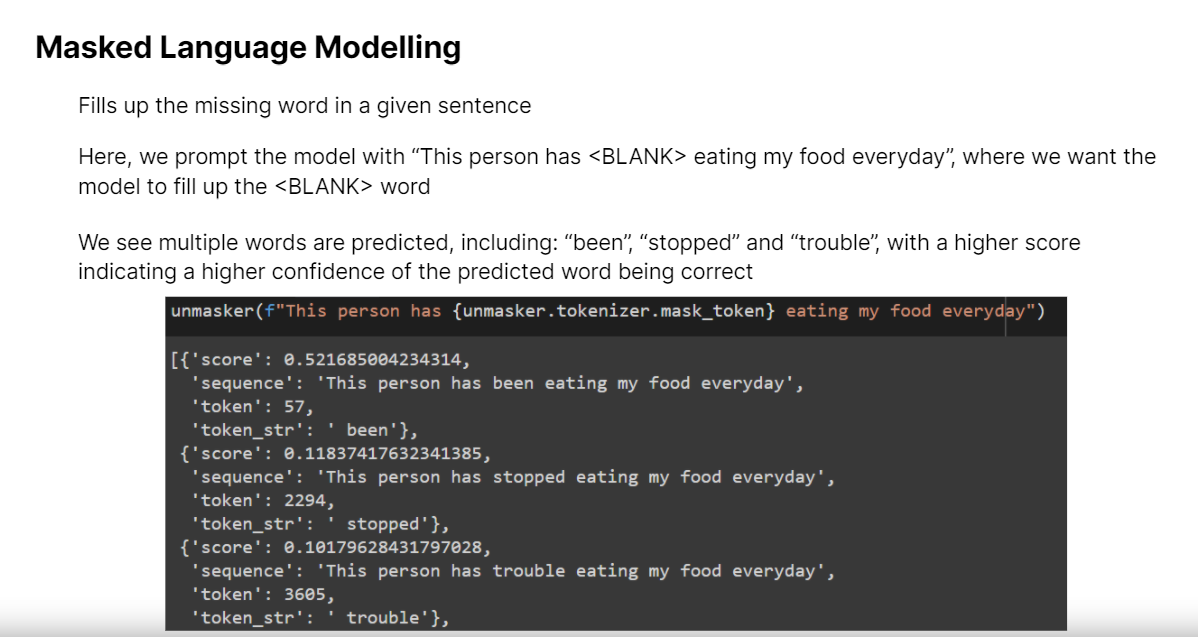
We then went on to explore the capabilities of NLP models, using the Huggingface library for NLP tasks including Text Summarization, Text Generation, Sentiment Analysis, Masked Language Modeling.
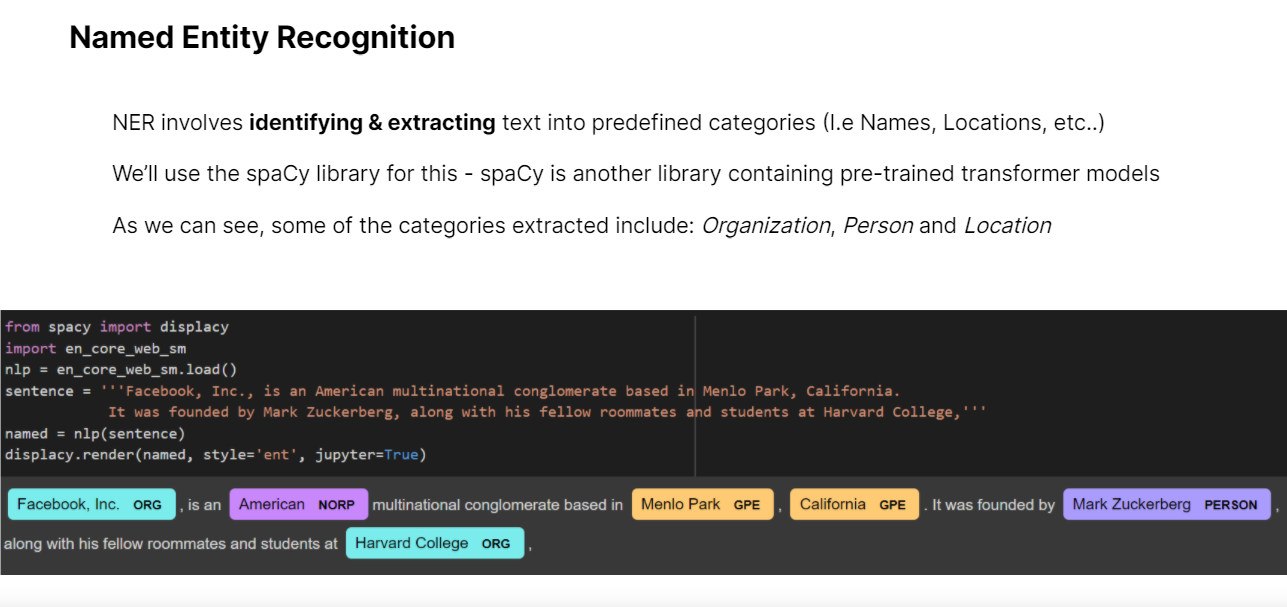
Named Entity Recognition using spaCy was also covered
Diving deeper, we moved on to Word Embeddings, which most State-Of-The-Art Machine Learning NLP models utilize.
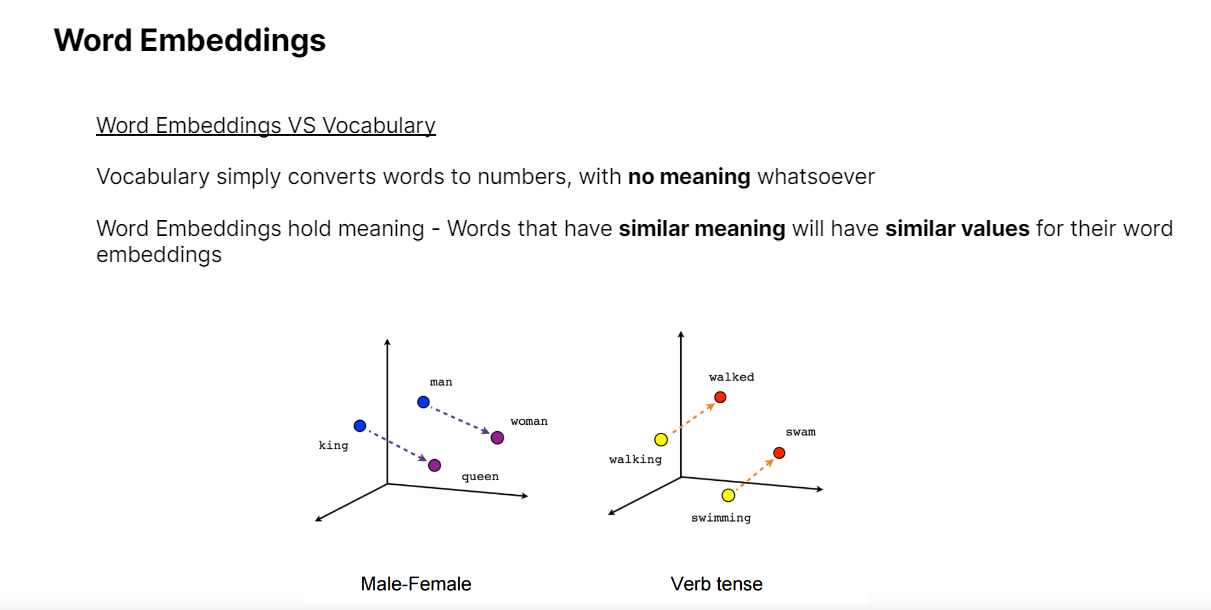
We utilized Tensorflow's Embedding Projector (https://projector.tensorflow.org/) to visualize embeddings in 3D space.
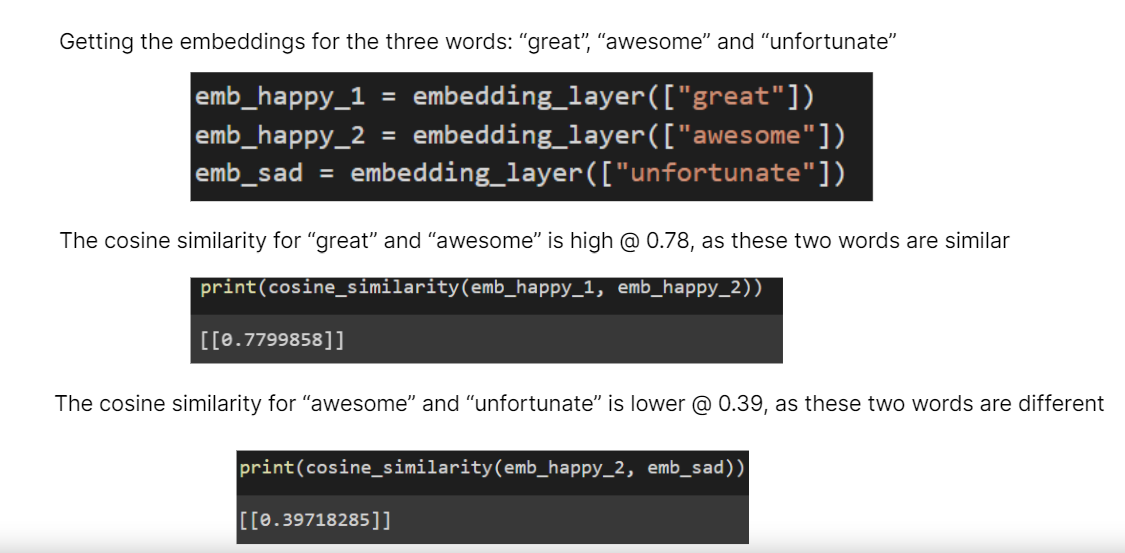
Pretrained Embedding Layers were obtained from Tensorflow Hub, for us to obtain our very own word embeddings.

Finally, to measure the similarity of two words, we utilized the Cosine Similarity function on the word embeddings.
Day 3: Time Series
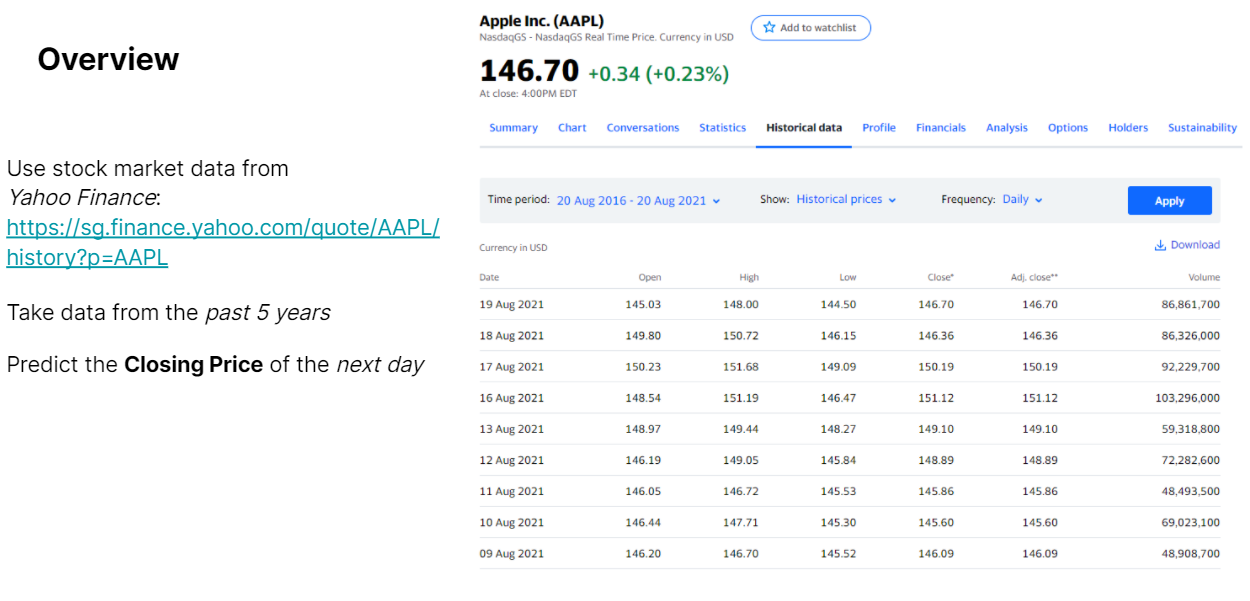
Stock Prediction with Deep Learning... We used Yahoo Finance to obtain the past 5 Years of financial Data for AAPL stock. We would then predict the closing price.
Today, we introduced preprocessing techniques for Time Series, most notably the Sliding Window method.

The Sliding Window method would allow us to create datasets for Time Series Prediction
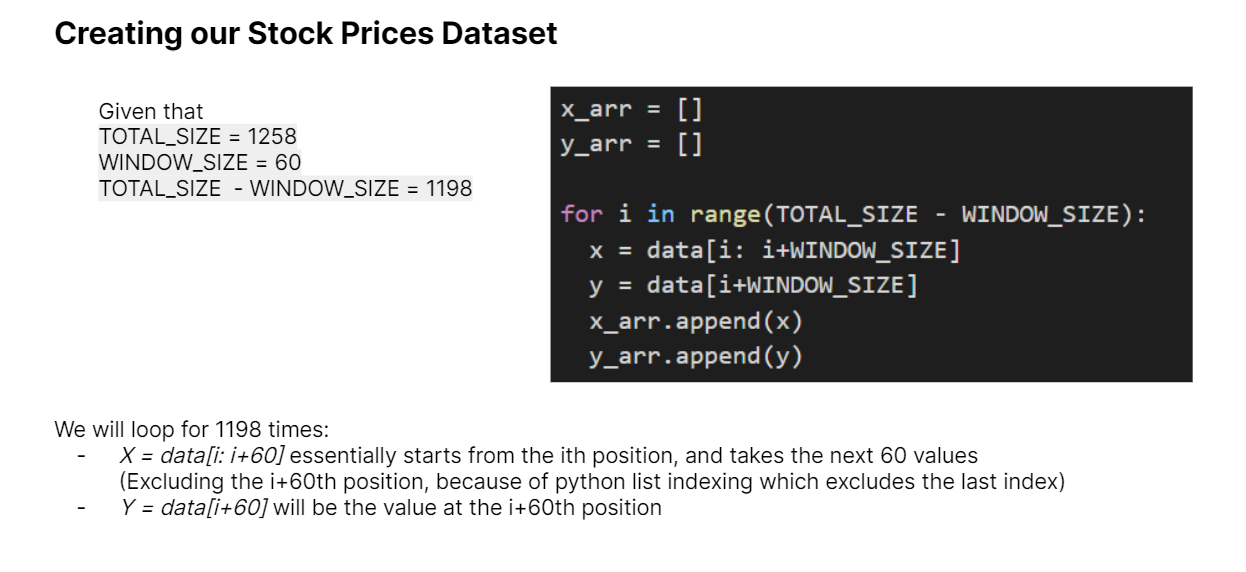
In our case, we had a window size of 60, meaning that we would use the past 60 days worth of closing prices to predict the next closing price.
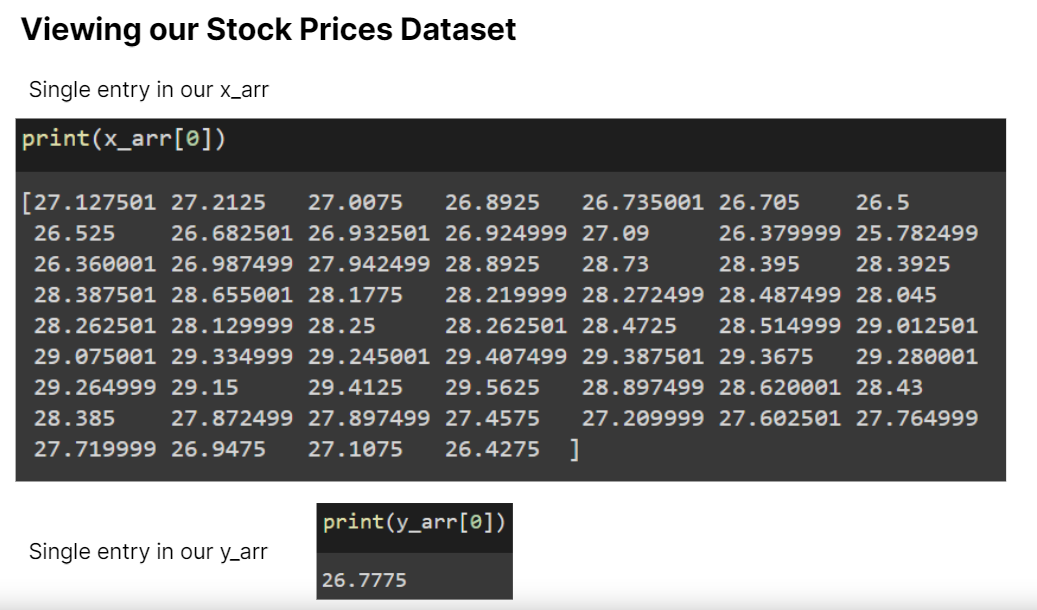
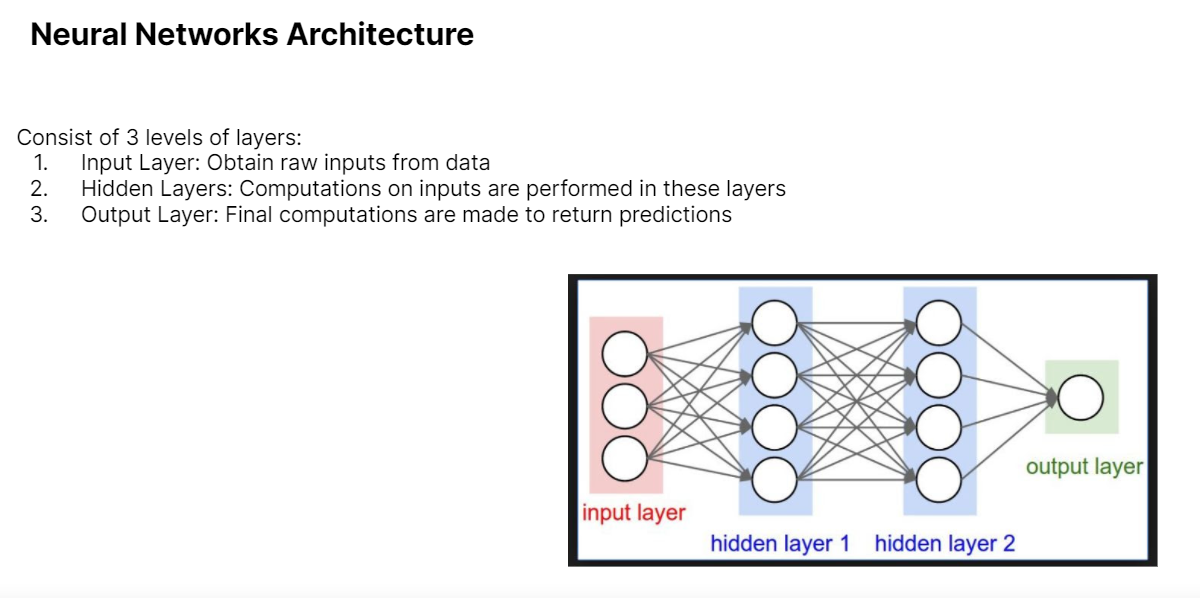
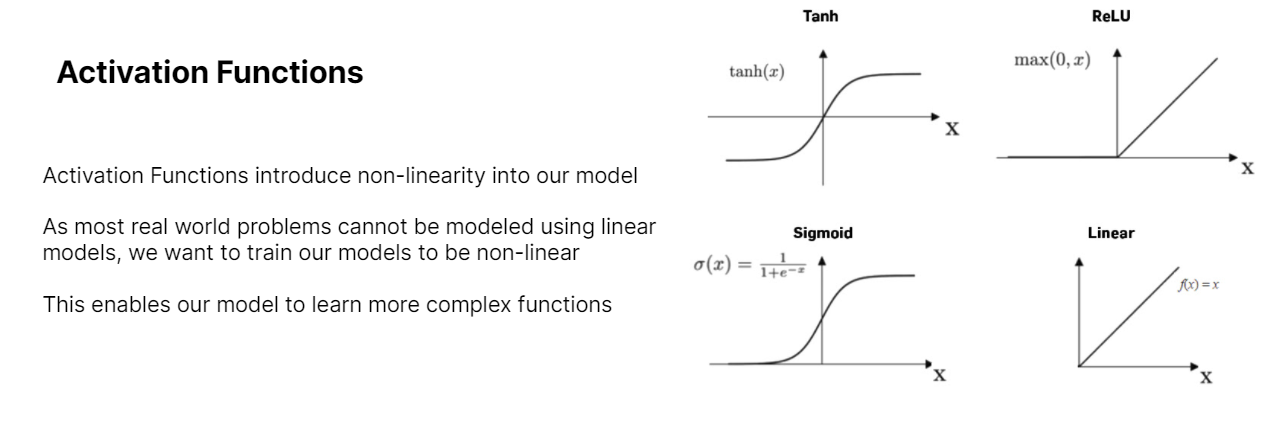
Moving on to Deep Learning, we covered concepts like Layer Types and Activation Functions.
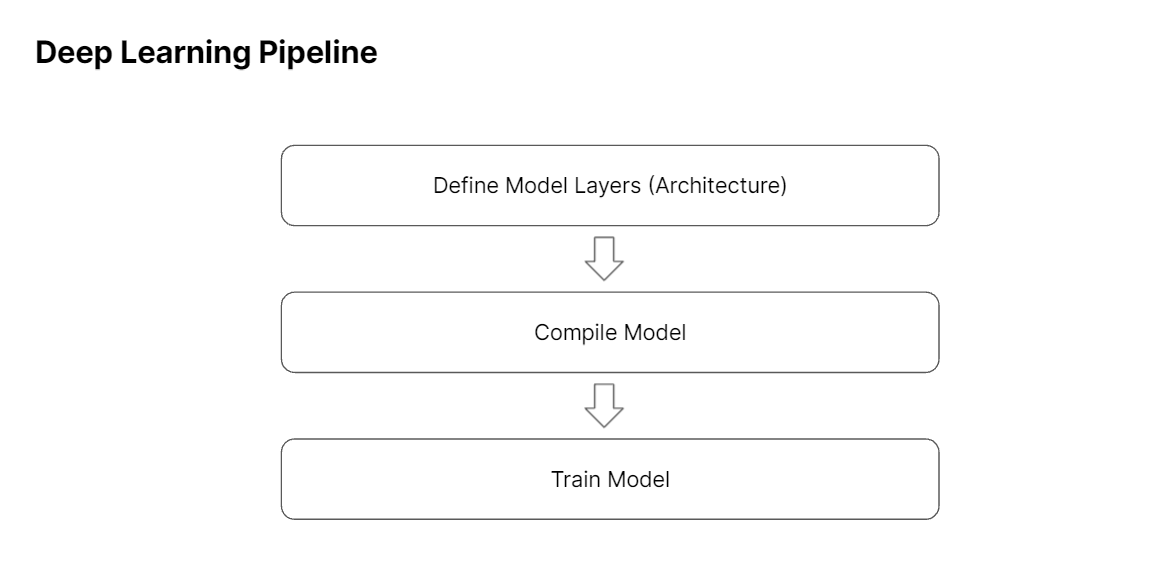
We then dissected the Tensorflow Deep Learning Pipeline: The 4-step process of Defining, Compiling, Training & Evaluating

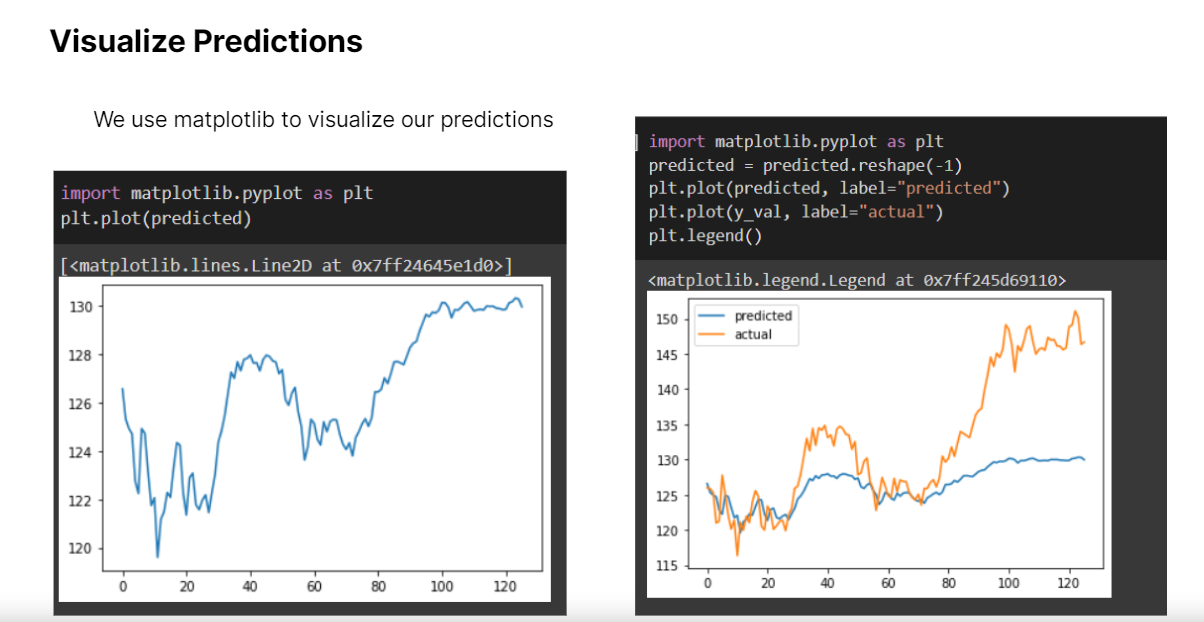
Finally, we made predictions on our Validation set and compared them to the actual prices (Funnily enough, this was during the Evergrande crisis.. so you could see a steep descent in global prices...) 🤪
Day 4
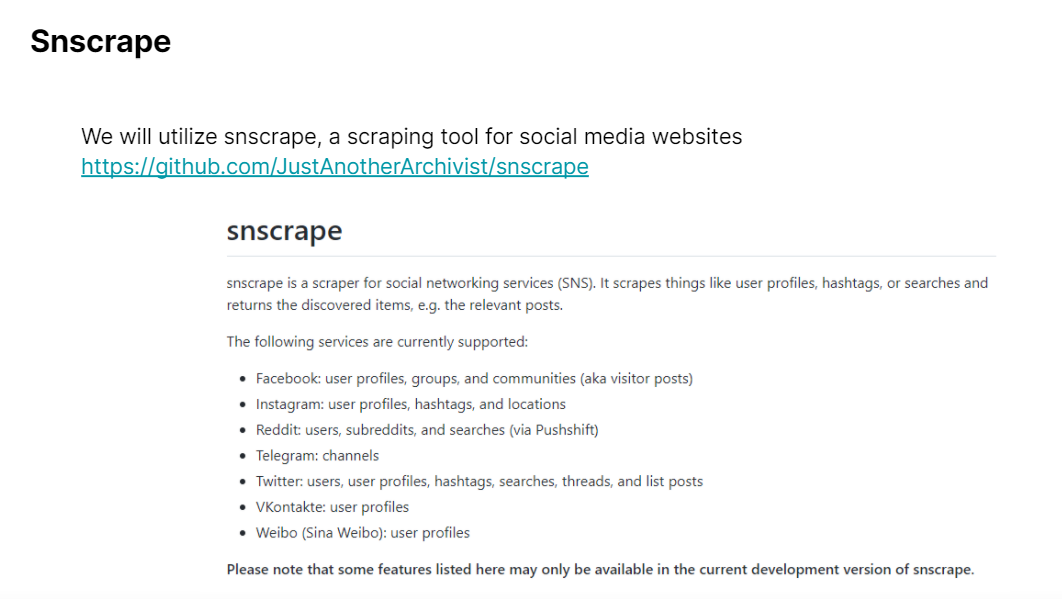
Here, we explore the malicious use cases of Artificial Intelligence. Our task for the day: Learn to impersonate someone's tweets.
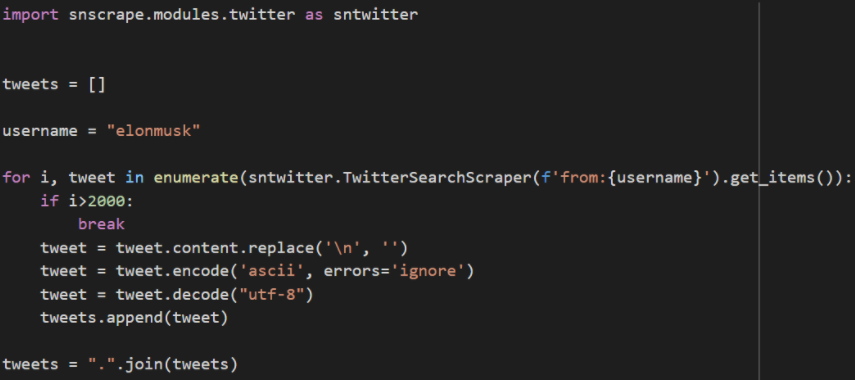
We utilized Snscrape for our Tweets Scraping. By specifying the username, we could extract a specified number of tweets from that person and write them out to a .txt file.
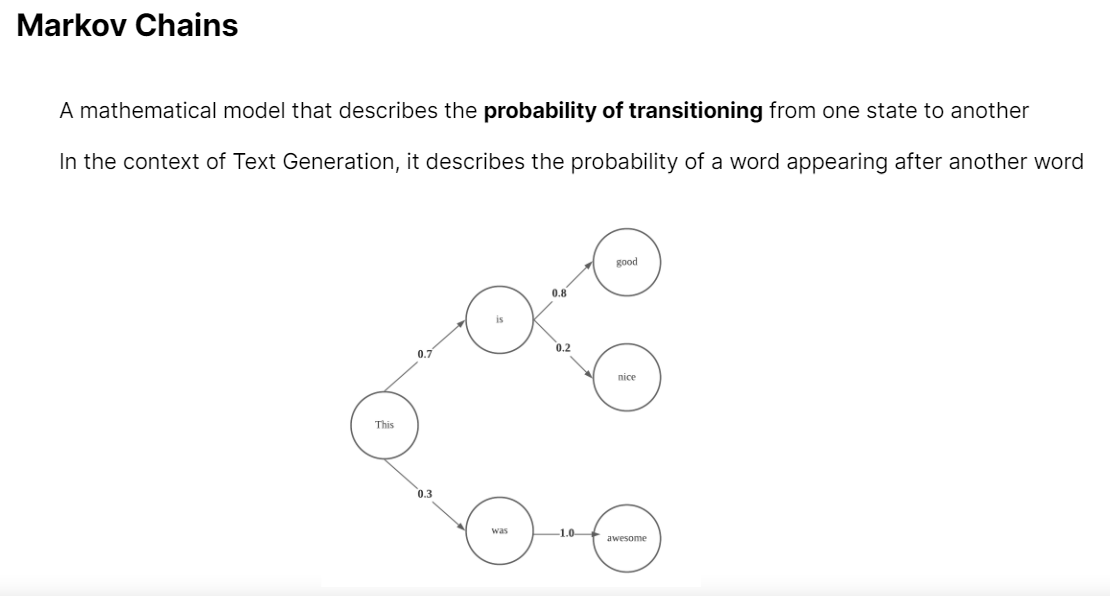
For Text Generation, we utilized Markov Chains.
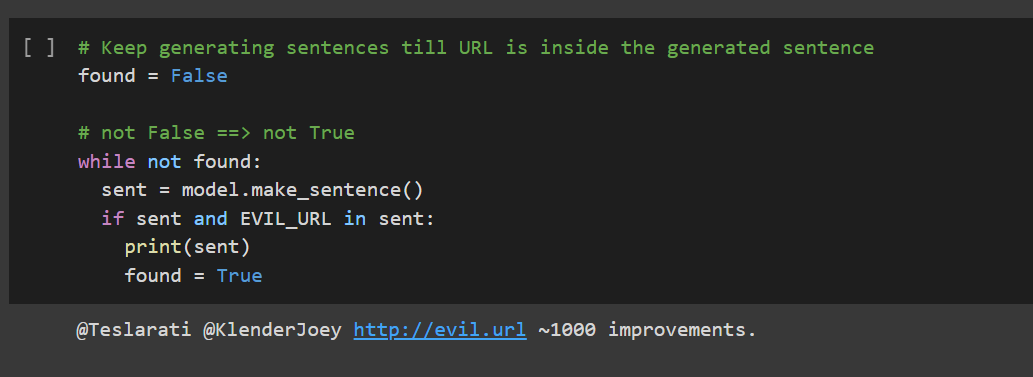
For our Malicious Use Case, we would replace all URLs in the tweets with our own malicious URL. We would then fit our Model on these preprocessed tweets.
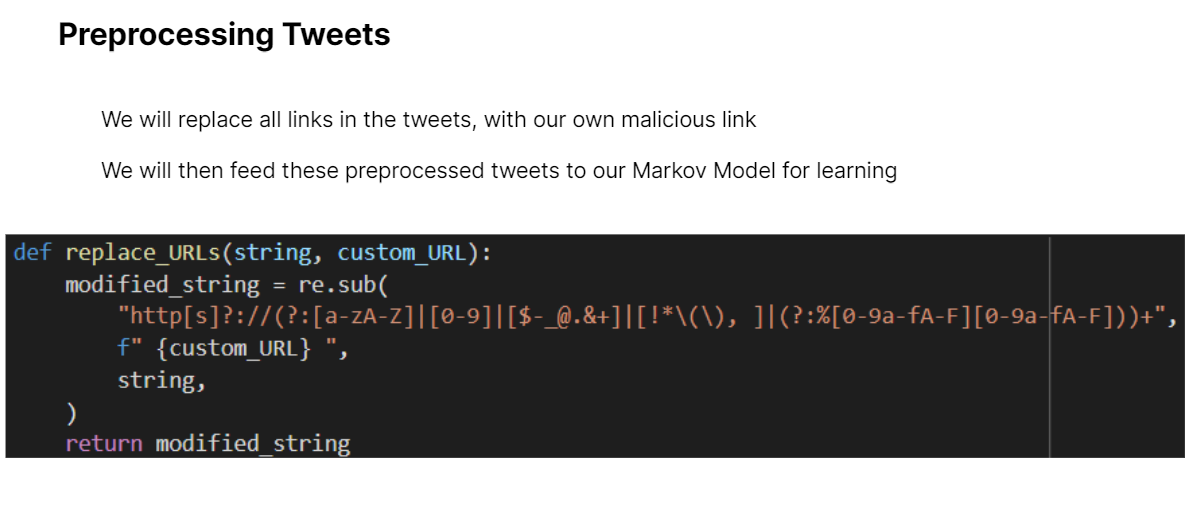
By fitting our model on these tweets, we are able to capture the linguistic style of that user, hence "impersonating" his/her tweets...
Day 5: Recommender System
Plunging into Recommender System, we covered two forms of Recommender Systems: Simple recommender system & Content-Based recommender system

For our Data Ingestion, we utilized the Kaggle API to download our Dataset: The MovieLens Dataset

For our Content-Based recommender system, we covered Text Preprocessing techniques including Bag-of-Words and TF-IDF. We then briefly touched on Matrix Factorization, before moving on to Cosine Similarity.
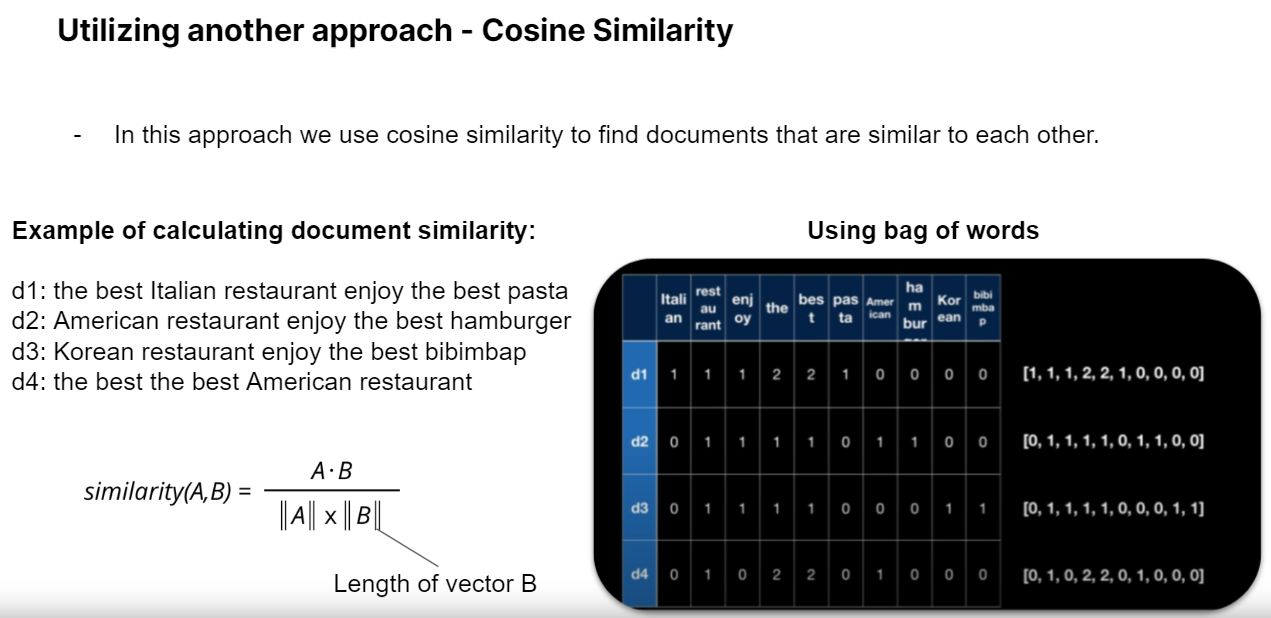
Finally, we trained our Content-Based recommender system using Cosine Similarity & used it to provide recommendations.

Afterword
We'd like to thank all our participants for making NYP AI Summer Camp 2021 a huge success! Not forgetting our Planning Team: Lim Jing Kai, Loy Jun Cheng, Tony Yu, Dylan Kok, Nuzul Firdaly & Alex Chien. Without them, the Camp wouldn't have been as exciting as we'd envisioned...
We'll continually come up with more exciting & updated AI content, so do keep a lookout for our future events 👀