
Tech Week 2022
During the September break, NYP AI hosted Tech Week in collaboration with the 5 other interest groups at NYP. The goal of this event was to teach Year 1 students the basics of Artificial Intelligence and how it can help people in their everyday lives
The outcome of this event was to give the students clarity on what AI, Machine Learning, and Deep Learning are, and then teach them how to create their own text summarizer using the streamlit library in Python. This web application can perform 2 simple functions
- it takes a link from a website or text that the user types in
- create a text summary using the huggingface transformers library
Inputs:

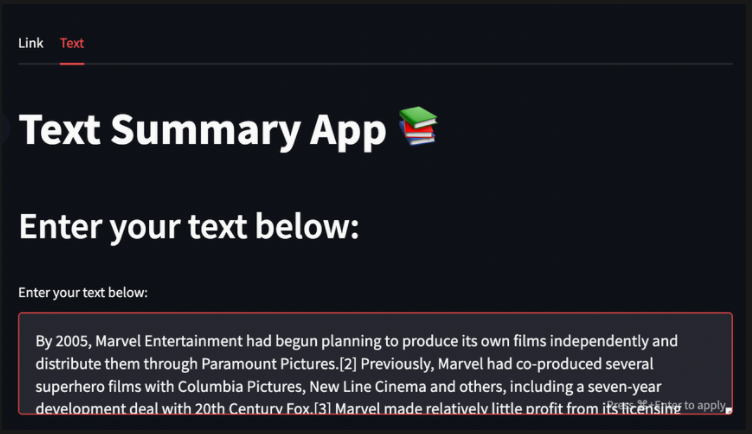
Output:

The Introduction
We first talked about artificial intelligence, machine learning, and deep learning, followed by the differences between them. For example, one of the differences is that in machine learning you have to do something called feature extraction, which is the process of labelling features. For example, if you want to identify a cat, you need to know what kind of ears it has, what kind of tail it has, etc. With Deep Learning, you do not have to label these features; instead, the Deep Learning model will identify the features for us. After discussing this, we talked about what neural networks are and the 3 different types of neural networks. We then introduced the participants to NLP, which they were able to understand by creating 2 types of text summarizers (abstractive and extractive). Finally, we used our text summarization in a streamlit webapp.
Natural Language Processing (NLP) project
We then talked about NLP and used a text summarization project to show the participants its possible applications. Before we started building the project, we introduced 2 types of text summaries
- Extractive text summarization: Finds the most important sentences in the text and creates a summary by combining these sentences together
- Abstract text summary: Creates a text summary in his or her own words by looking at the main ideas in the text
The first step of our project was to collect the text data that we wanted to summarize. We wanted the app user to have the freedom to summarize content from whatever website they wanted. So we used the requests and beautifulsoup libraries to collect the text data
The requests library helped us send a request to the website and retrieve the HTML page of the website, while the beautifulsoup library allowed us to retrieve the text from the HTML page essentially acting as a parser.
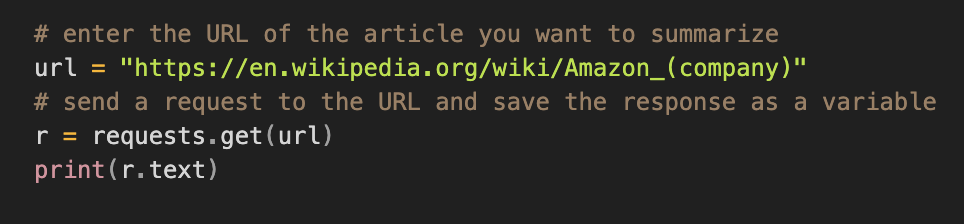
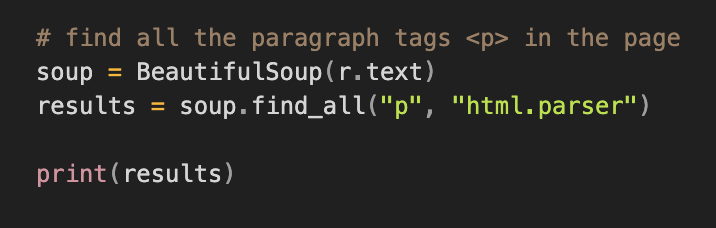
After collecting all the paragraph tags, we need to extract the text from the paragraph tags and combine them into a sentence. After that, we simply use some regex to clean up the text. This is how we get our final text.
Now we need to do something called tokenization. This involves breaking down the text into smaller units called tokens. We need to create 2 types of tokenizers: Word Tokenizers and Sentence Tokenizers.

After we have created our tokenizer, we need to create a word frequency table. This table, as the name implies, records the number of occurrences of each word in the table. However, this table does not include punctuation or stop words, which are words that do not add any value to the text.

After creating our word frequency table, we find that certain words are more common than others. To reflect the true meaning of a word, we had to perform what is called document length normalization. See the slide below for more information.


After normalization, we need a sentence scores table that shows the importance of each sentence in our text, which in turn allows us to select the most important sentences in the text. Below is the code to accomplish this in python.

Now that we have our sentence score table, we can pick out 30% of the total sentences with the highest score. To do this, we use the nlargest function from the heapq module. The nlargest function takes 3 arguments: the number of sentences as the first argument, the table of sentence scores as the second argument, and the key of this table of sentence scores.

Abstractive text summary
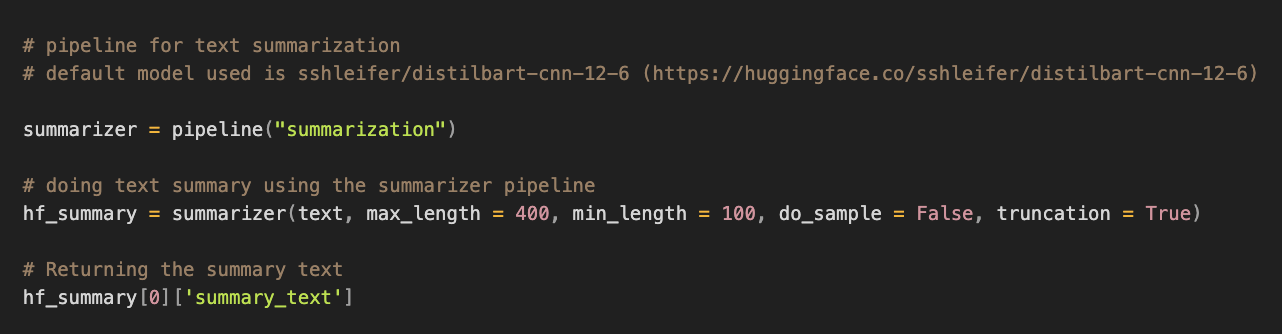
Abstractive text summary is the process of creating the text based on the main ideas. So you can think of it as the AI writing the text in its own words instead of copying the main sentences. For abstract text summarization, we used the huggingface transformers library.
- First, we need to create a pipeline object and assign it a task, which in our case is the summarizer.
- Then we insert our text into the summarizer, set the maximum length of the summary to 400 words
- The minimum length to 100
- Set do_sample to false. This parameter controls what type of decoding takes place.
After that, we simply return our summary text.
Streamlit webapp
Streamlit is an app framework in Python that allows us to build web apps for data science and machine learning. It is very popular because it is very easy to use and compatible with various libraries like keras, scikit learn, tensorflow, etc. Streamlit webapps are written in Markdown, which allows us to easily create good looking webapps. Since we wanted the website to give the user a choice between entering a website link or text, we created a navigation bar with these options.

After that, we simply put a heading and an input field on the page. To generate the text summary, we used the huggingface transformers library to accomplish our task.
By the end of the event, participants were now more familiar with the basic concepts of AI and knew how to use the various tasks in the huggingface transformers library to accomplish various NLP tasks, and they also knew how to use streamilt to create nice-looking web apps.
Afterthoughts
We would like to thank all participants for attending. We hope you were able to learn more about AI and its possibilities. We will be back with more content in the future, so stay tuned!
