
Tech week is back this year and we have come up with a better and more interesting topic that has been taking the world by storm - “Generative AI”. The workshop was help on day 2 of tech week and physically at NYP after the covid-19 break.
The aim of the event was to educate participants on the basics of generative AI as well as introduce them to the many open source models that they can use in their projects and how they can quickly finetune them to answer questions based on their desired dataset.
The event began with us giving a very quick introduction to AI, machine learning and deep learning and where generative AI fits into all this.
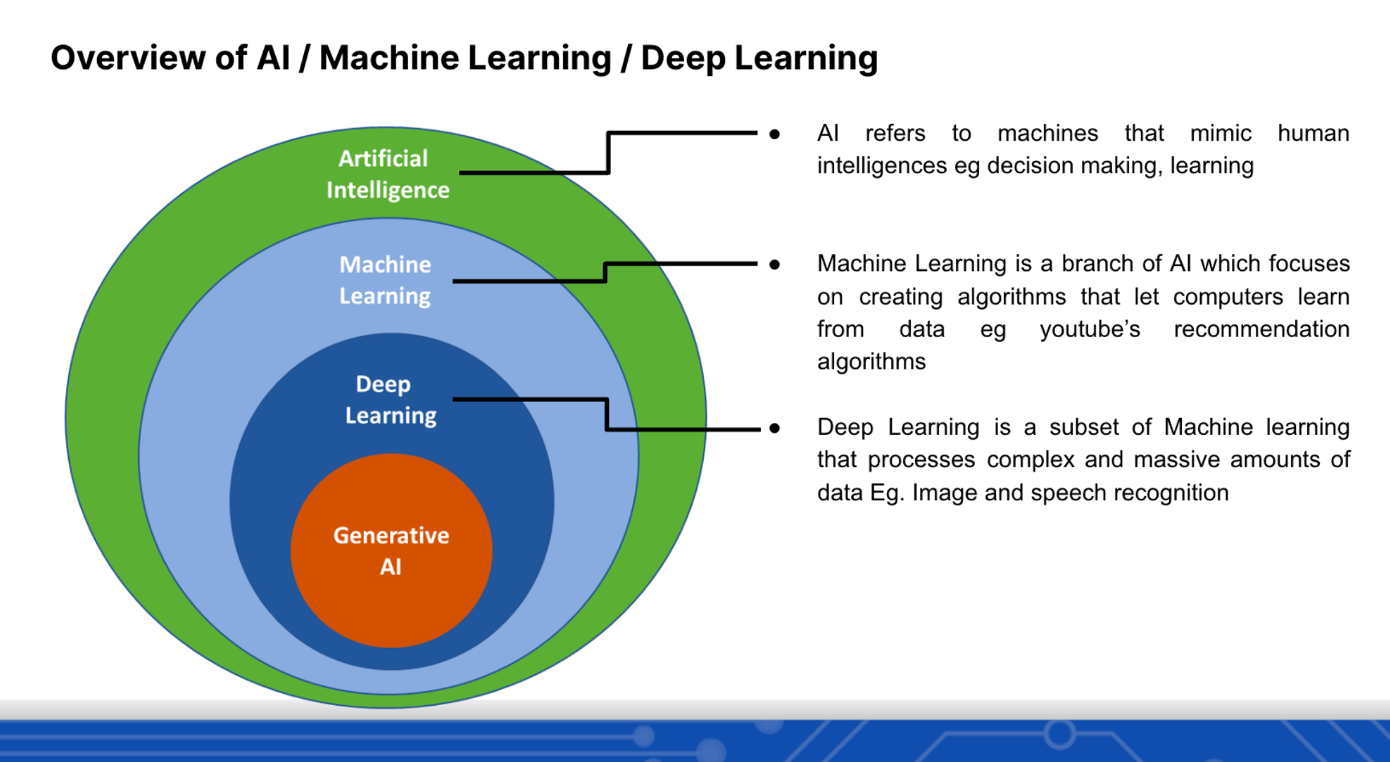
After this we gave a brief intro to generative AI, which is the branch of AI that can create generate new content from the data that it is being trained on. The most popular example of this is chatGPT which has been trained on a large corpus of text and is very good at text generation. Similarly we have models that can generate images (https://huggingface.co/spaces/stabilityai/stable-diffusion), music (https://huggingface.co/spaces/facebook/MusicGen) and now even video (https://huggingface.co/PAIR/text2video-zero-controlnet-canny-arcane). Feel free to play around with these if you like, they are all open source and freely available to the public.
we also spoke about 3 different generative models which were Generative Adverserial Networks (GANs), Denoising Diffusion Models, and Variational Autoencoders.
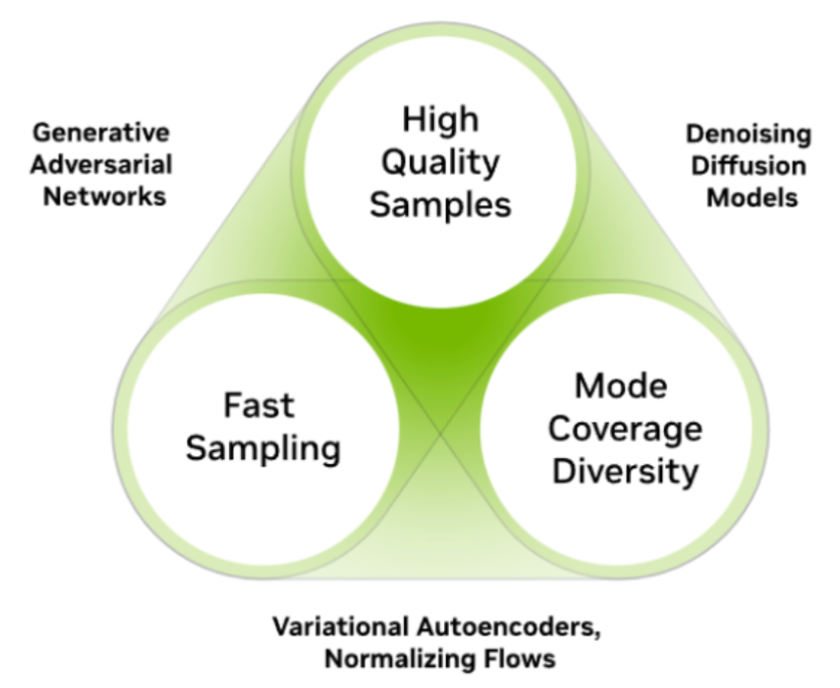
Some of the key points that were highlighted can be seen in the table below:

TEXT GENERATION
After talking about how generative AI models work, we moved onto talking about text generation which was a part of Natural Language Processing (NLP). AI uses NLP to make sense of textual user inputs by analysing the grammatical structure and of sentences and individual meaning of words, then uses algorithms to extract meaning and deliver outputs.
Coming back to text gen, we spoke about how the next word to be predicted in the sentence will have a high probability of occuring after the word by analysing the patterns and relationships within the training data.

However, this approach doesnt work especially if we want to preserve the context of the sentence. The problem was that models couldnt remember long sequences of text and this was due to something called fixed length context vectors. This is where we introduced the transformers concept.

The transformer has something known as the attention mechanism which allows the model to focus on specific parts of the input and give more weight to them when producing an output. Multihead attention was where there would be multiple focus points at once which captures different aspects of information. Finally positional encoding would ensure that the model can recognize the word order.
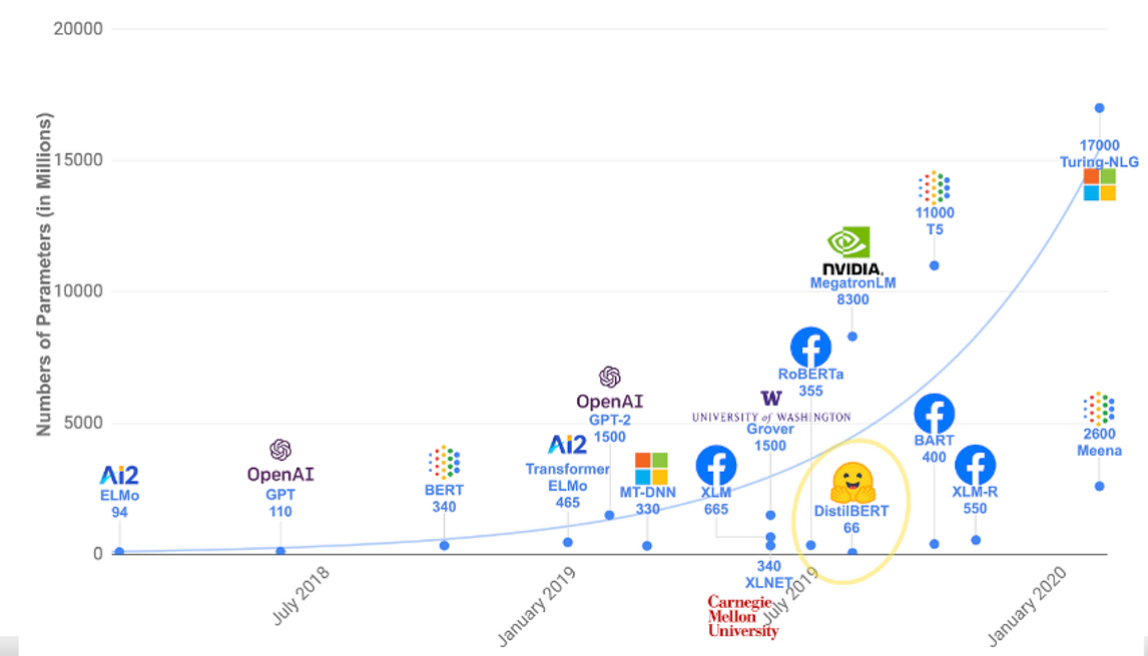
The transformers mode was introduced in a paper titles “Attention is all you need”2017 and has come a long way since then with many models such as the GPT and BERT models being transformer neural networks.
Improving Text Generation Models
To improve text generation models there were 3 ways we could have done it.
- The easiest would have been prompt engineering, finding a suitable way to prompt the model so that the desired output can be achieved check out prompt engineering guide (https://www.promptingguide.ai/techniques/zeroshot) which is a very guide resource talking about concepts like zero shot, few shot and chain of thought prompting.
- The second would be Fine tuning which is the process of adapting pre-trained models to perform specific tasks or operate within particular domains. Techniques like quantized low rank adapters (QLoRA) and Performance Efficient Fine Tuning (PEFT) can be used. However this is a very time consuming and computationally expensive process
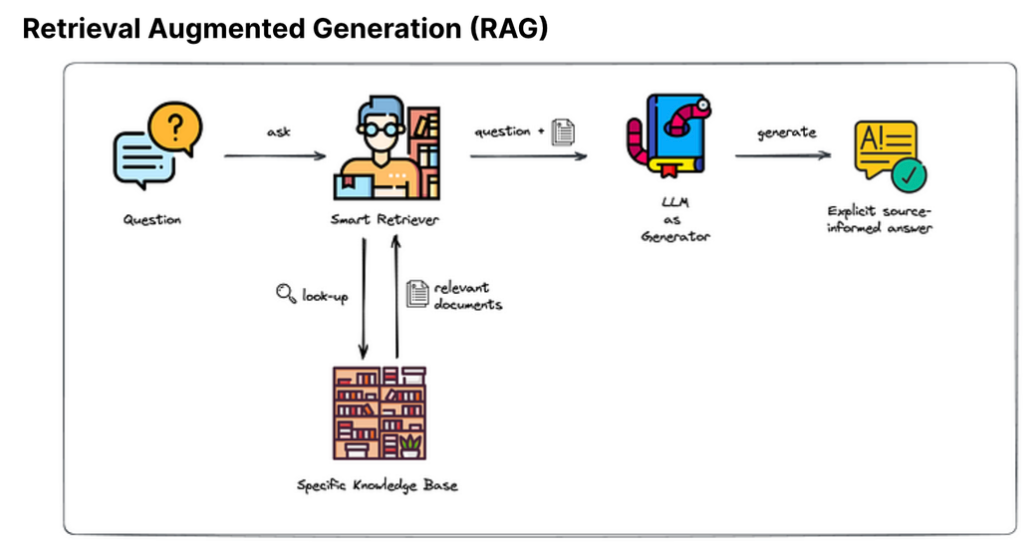
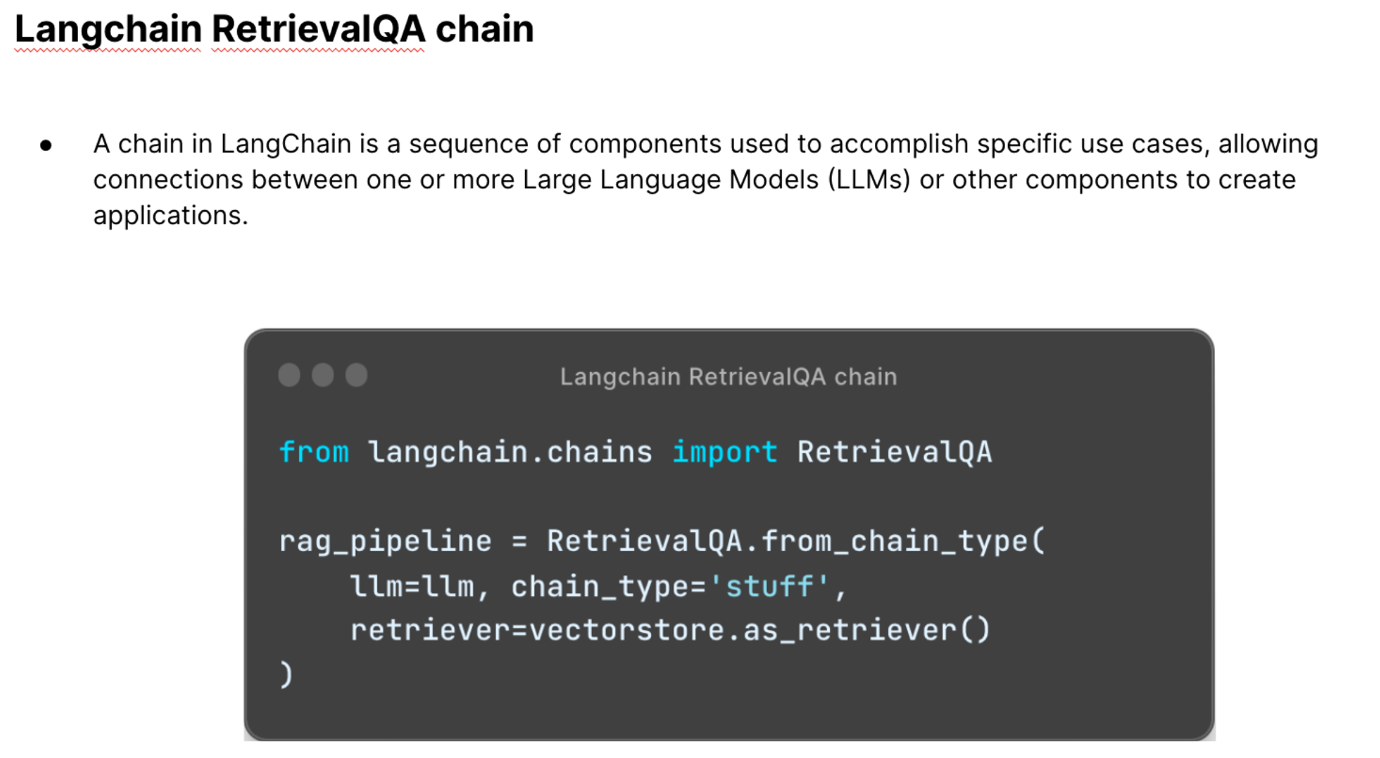
- The third is retrieval augmented generation which uses both retrieval-based and generative models to produce more informed and coherent responses. It can be explained in 4 simple steps:
- Query Formulation:
- The process begins with the formulation of a query based on the input received. This query is designed to retrieve relevant information from a given dataset or knowledge base.
2. Information Retrieval:
- The formulated query is then used to fetch relevant documents or data snippets from the external dataset or knowledge base. This is typically done using a pre-trained retriever model which ranks the documents based on relevance to the query.
3. Contextual Merging:
- The retrieved information is combined with the original input to form an augmented context. This augmented context now contains both the original input and the additional information retrieved from the external source.
4. Response Generation:
- A generative model, such as a Transformer-based model, is then employed to generate a response based on the augmented context. This response is expected to be more informative and accurate as it's based on additional external information.
RAG practical
This practical was designed to shows users how to use retrieval augmented generation on their own dataset. For the practical we used the arxiv research papers dataset. The first step was to convert the text to embeddings. To do that we needed to craete an embedding pipeline. We used sentence transformers model to do this for us.

And then we had to use this pipeline. We can see that the embeddings have been produced for the 2 sentences in the docs list.
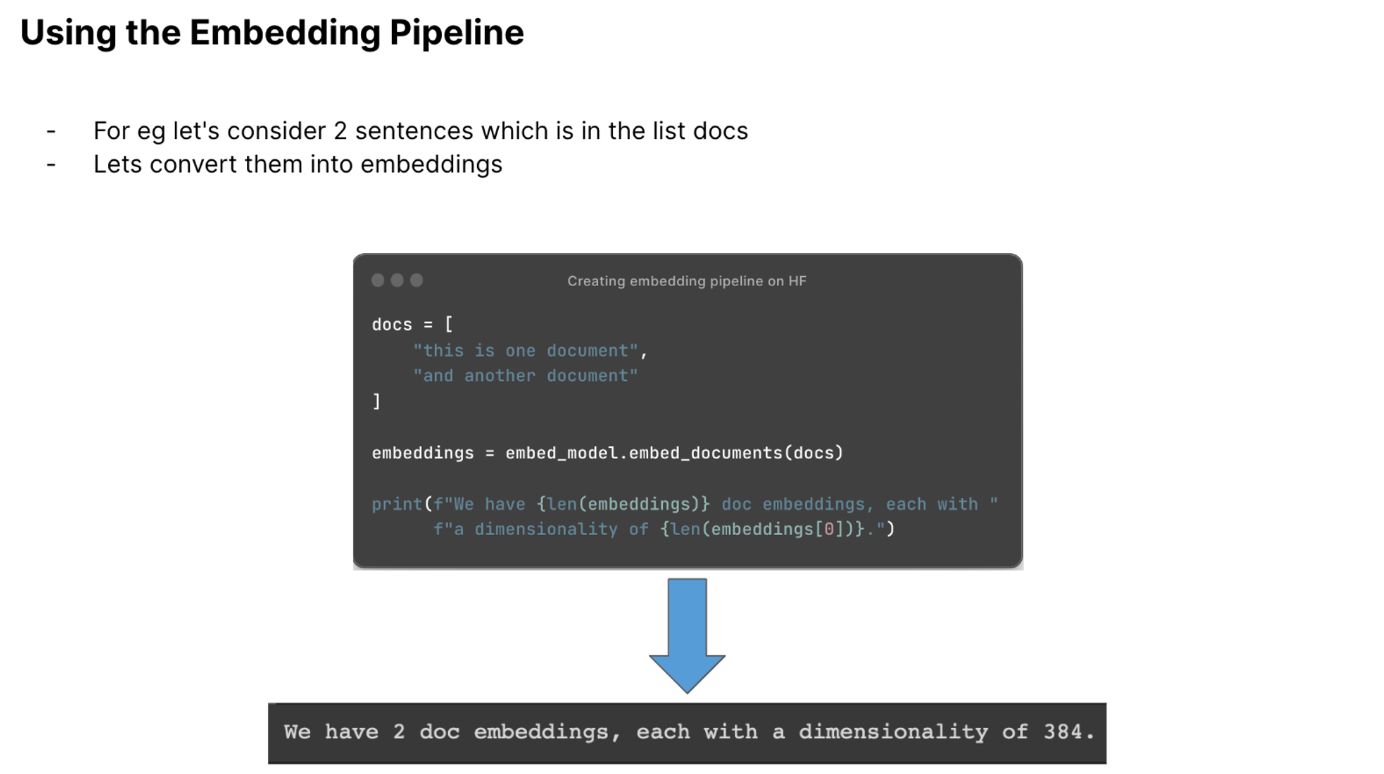
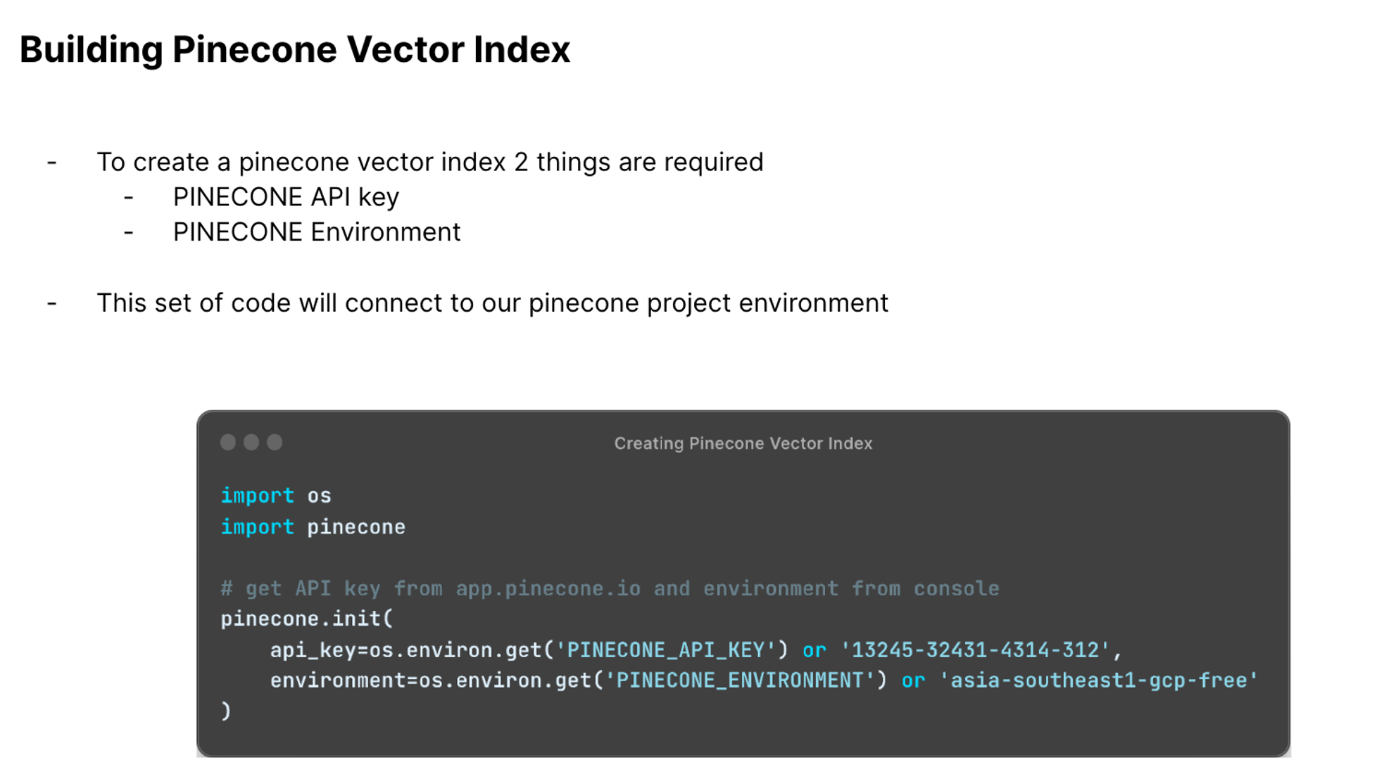
To store the embeddings we had to use a vector database. For this we made use of pinecone which had a very generous free tier (https://www.pinecone.io/).
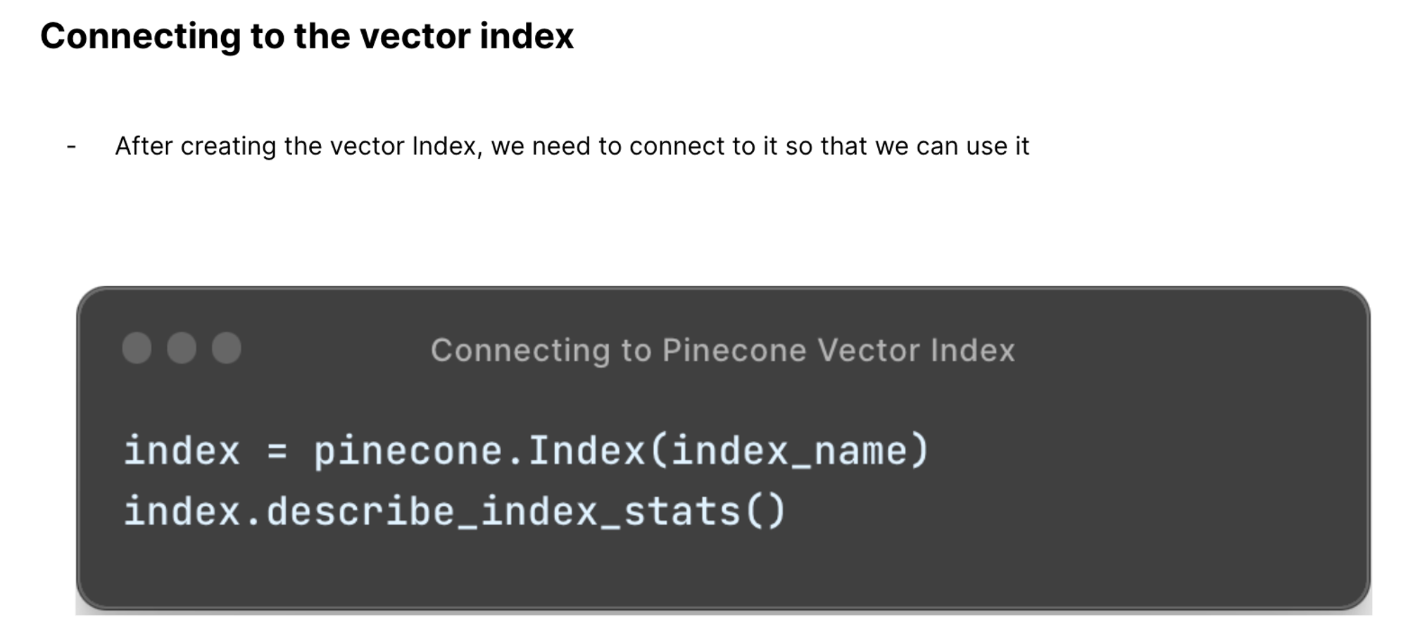
The vector index, a data structure used to organize and search vector data efficiently, was created.
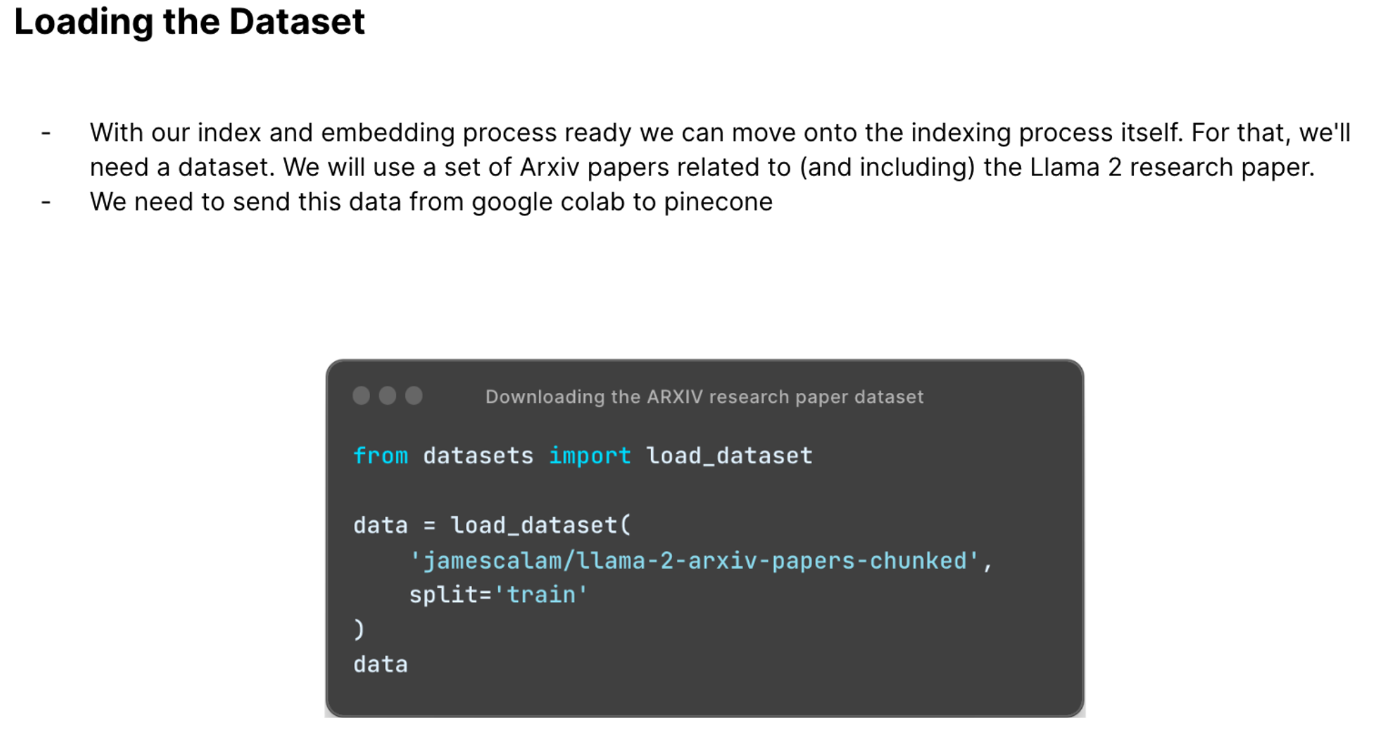
Our dataset was of ArXiv research papers. Below is the code to load the datasets.
This data was then processed to have 3 key components: Ids, Embeds, and metadata. This was then inserted into the vector database.

We then made use of langchain for the retrieval QA generation.

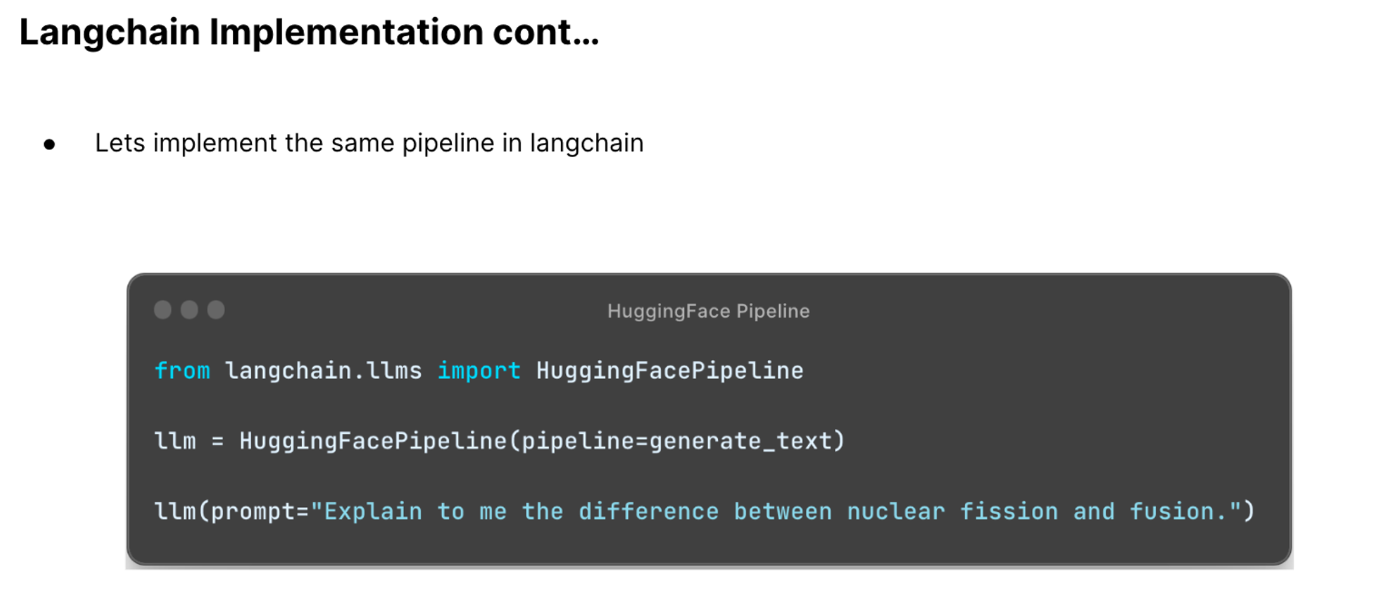
After all that code it was finally time to run it to see if it worked. Below is the comparison of the same response with and without RAG.

Image Generation and Captioning Practical
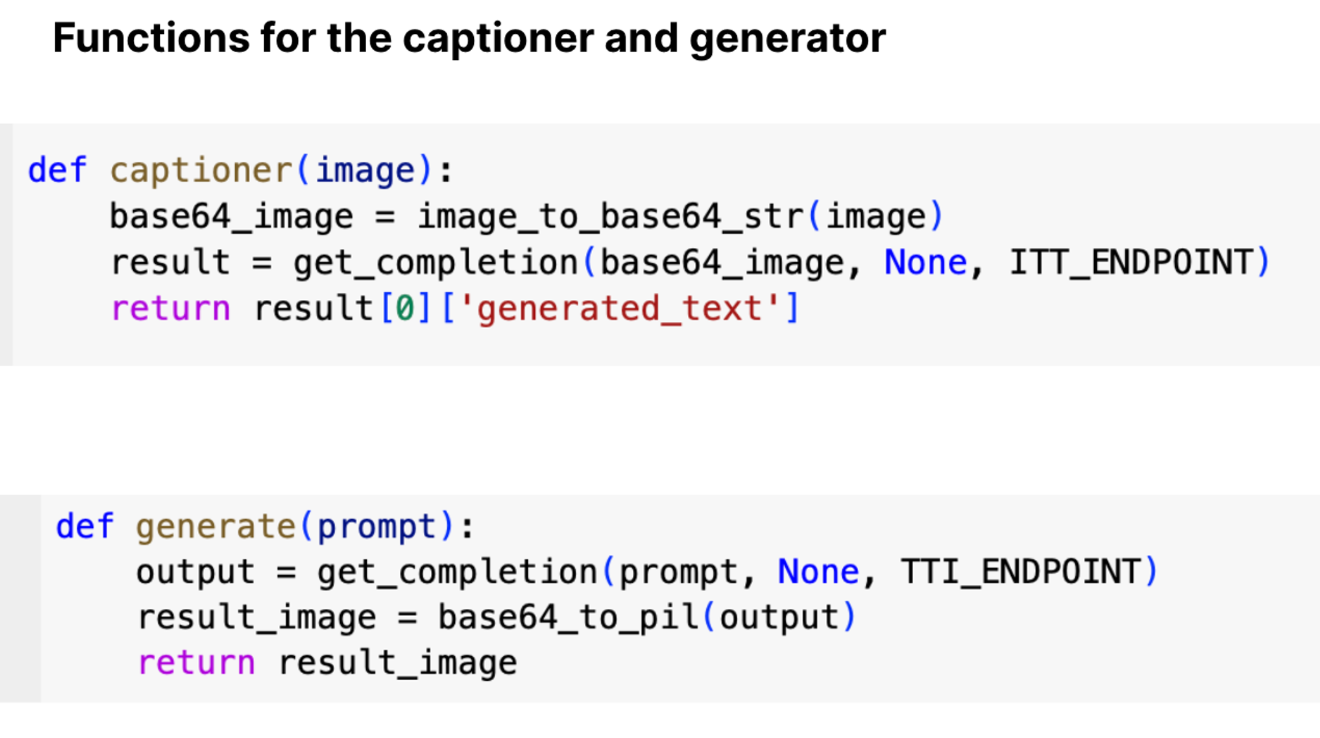
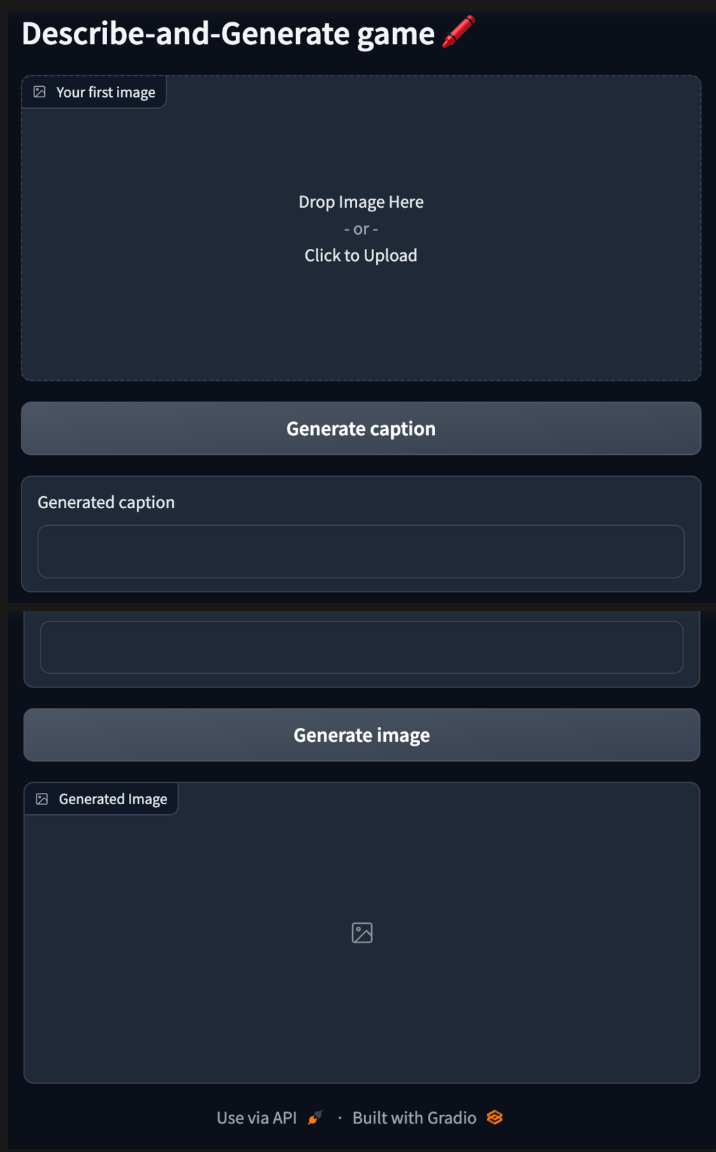
After text generation we moved on to our image generation practical. The goal was to build a simple interface using gradio where users could get the caption of the images by uploading them or type in a prompt to generate images.
Text to image model: https://huggingface.co/runwayml/stable-diffusion-v1-5
Image to text model: https://huggingface.co/Salesforce/blip-image-captioning-base
We made use of the model endpoints and made a simple interface that looks the one below:
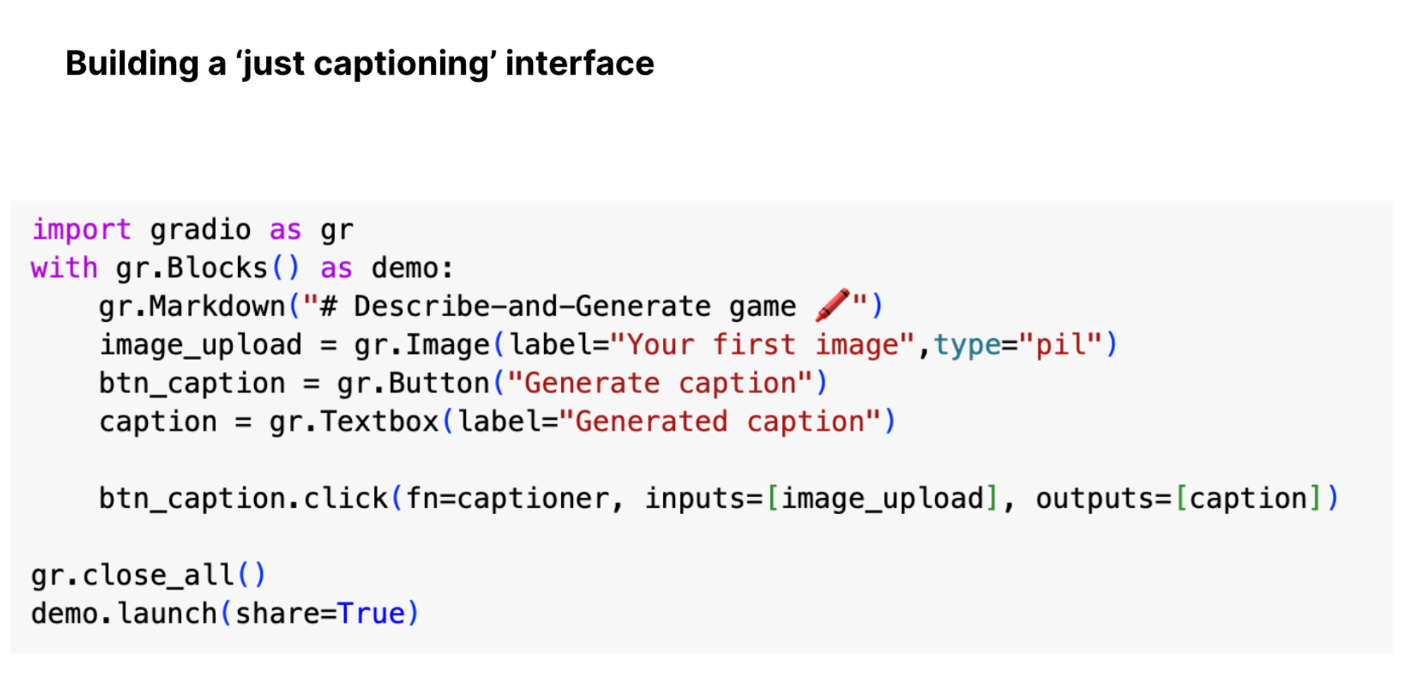
Gradio interface code for text captioning:
Gradio interface code for image generation

As the event wrapped up, many participants expressed how engaging and informative they found it. Even with a smaller crowd due to the in-person format, the event allowed for easy clarification of doubts and valuable networking among attendees. The hands-on practical sessions were a highlight, as everyone could follow along, making the learning experience both enriching and interactive.

Links:
Workshop Materials: https://drive.google.com/drive/folders/1MHdWMrzNQ_au4drMEjYbH1Ukgcs-prsr?usp=drive_link
NYPAI Instagram: https://www.instagram.com/nyp_ai/
NYPAI Linkedin: https://www.linkedin.com/company/nyp-ai/mycompany/
NYPAI Membership Form: https://forms.gle/H3C4afosUJVvBgKC6
